
빅데이터 분석기사 9회 실기까지 합격했습니다!!
실기 시험은 변수가 너무 많고, 실수가 있을 수 도 있어서 성적 공개 2시간 전부터 엄청 긴장했습니다
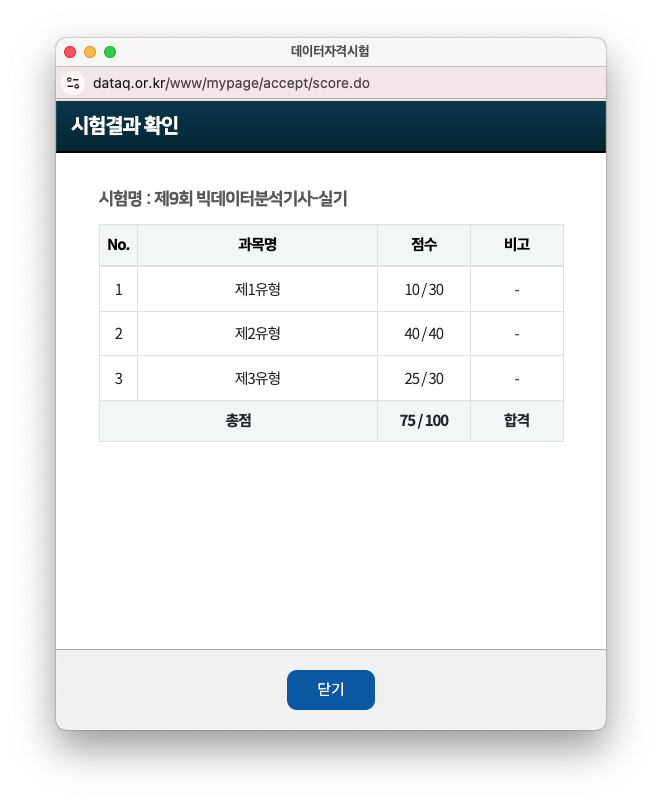
엄청 두근 거리는 마음으로 4시에 결과를 확인했는데, 사전점수 합격이었습니다!!
빅분기 필기 합격 후에 실기 준비하기가 얼마나 귀찮던지... 이번 시험 보지 말까 고민도 했지만,
친구가 시험 보라고 보라고 엄청 설득해서 4일 전부터 공부를 시작했습니다.
 |
 |
빅분기 시험에 대한 소개나 기출 복기는 다른 분들이 잘 정리 해두셨으니
저는 제가 4일동안 어떻게 공부했는지 공유하겠습니다~!
<빅데이터 분석기사 4일 공부법>
Python을 어느 정도 사용할 수 있었기 때문에 2유형과 3유형에 집중했고, 1유형은 아예 패스했습니다.
(그래서 1유형은 1문제 밖에 못풀었습니다..ㅠㅠ)
1일차 : 2유형 공부하기
우선 데이터마님의 2유형 연습문제를 모두 풀고 저만의 코드를 정리해두었습니다.
분류 -> RandomForestClassifier, 회귀 -> RandomForestRegressor
혹시나 원-핫 인코딩 (get_dummies) 방식이 오류가 날까봐 LabelEncoder()도 준비를 했습니다.
랜포_분류
import pandas as pd
#데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/X_test.csv")
# 만약 데이터가 2개 주어지면
train = pd.read_csv('')
test = pd.read_csv('')
x_train = train.drop(['종속변수'])
y_train = train['종속변수']
x_test = test
x_train = x_train.drop(columns = ['CustomerId', 'Surname'])
y_train = y_train.drop(columns = ['CustomerId'])
x_test = x_test.drop(columns = ['CustomerId', 'Surname'])
import numpy as np
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, accuracy_score, recall_score
print(x_train.shape, y_train.shape, x_test.shape)
# category나 object 있는지 확인 > object 있음 > 인코딩 필요
total = pd.concat([x_train,x_test], axis = 0 )
# Object -> LabelEncoder
# total['Geography'] = LabelEncoder().fit_transform(total['Geography'])
# total['Gender'] = LabelEncoder().fit_transform(total['Gender'])
#변수처리(원핫 인코딩)
total = pd.get_dummies(total)
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
# 훈련/ 검증데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
# 학습
model = RandomForestClassifier()
model.fit(x_train, y_train) #학습
y_pred = model.predict(x_val) #예측
acc = accuracy_score(y_val, y_pred) #평가
f1 = f1_score(y_val, y_pred)
recall = recall_score(y_val, y_pred)
print(acc, f1, recall)
y_result = model.predict(x_test)
pd.DateFrame({'pred': y_result}).to_csv('result.csv', index = False)
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e3_p2_train_.csv')
test = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e3_p2_test_.csv')
x_train = train.drop(columns = ['ID', 'TravelInsurance'])
y_train = train['TravelInsurance']
x_test = test.drop(columns = ['ID'])
import pandas as pd
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
total = pd.concat([x_train, x_test])
total = pd.get_dummies(total)
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_pred = model.predict_proba(x_val)[:,1]
auc = roc_auc_score(y_val, y_pred)
print(auc)
y_result = model.predict_proba(x_test)[:,1]
pd.DataFrame({'ID': test['ID'].values, 'proba': y_result}).to_csv('', index=False)
⭐️ 주의할 점 ⭐️
1. roc_auc_score을 구할때는 model.predict_proba(x_val)[:,1] 를 해야함
2. 다중분류일때 average='macro'
precision_score(y_true, y_pred, average='macro')
recall_score(y_true, y_pred, average='macro')
f1_score(y_true, y_pred, average='macro')3. 결과 제출할때 ID도 같이 제출해야 한다면 pd.DataFrame({'ID': test['ID'].values, 'proba': y_result}).to_csv('', index=False)
랜포_회귀
import pandas as pd
#데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/X_test.csv")
print(x_train.shape, y_train.shape, x_test.shape)
y_train.head()
x_train = x_train.drop(columns = ['StudentID'])
y_train = y_train['G3']
x_test = x_test.drop(columns = ['StudentID'])
print(x_train.shape, y_train.shape, x_test.shape)
total = pd.concat([x_train, x_test], axis = 0)
total.shape
total.info()
total = pd.get_dummies(total)
import numpy as np
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, mean_absolute_percentage_error
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
model = RandomForestRegressor()
model.fit(x_train, y_train)
y_pred = model.predict(x_val)
mae = mean_squared_error(y_val, y_pred)
rmse = np.sqrt(mean_squared_error(y_val, y_pred))
print(mae, rmse)
y_result = model.predict(x_test)
pd.DataFrame({'pred':y_result}).to_csv('/content/drive/MyDrive/빅분기/2유형_분류1.csv', index = False)
2 ,3 일차 : 3유형 공부하기
3유형은 따로 책이나 정보가 부족해서 블로그 후기들을 찾아봤습니다.
1. 로지스틱 회귀 Logit
import numpy as np
import statsmodels.api as sm
from statsmodels.api import Logit
df = df[['Survived', 'Sex', 'Age', 'SibSp', 'Parch']]
formula = 'Survived ~ Sex + Age + SibSp + Parch'
model = Logit.from_formula(formula, df).fit()
print(model.summary)
# Sex 가 범주형으로 하고 싶으면 C(Sex)로 바꾸면 됨
# 오즈비
odds_ratio = np.exp(model.params['Age'])
# 오즈비 5배 증가
odds_ratio = np.exp(model.params['Age'] * 5)
# 오차율
y_true = df['Survived']
y_pred_proba = model.predict(df)
y_pred =(y_pred_proba >= 0.5).astype(int) # 임계값 0.5를 기준으로 생존 여부 예측
error_rate = (y_pred != y_true).mean()
print(error_rate)
# 잔차 이탈도
residual_deviance = -2 * model.llf
# 로짓 우도
model.llf
# aic, bic
print(model.aic)
print(model.bic)
2. 선형회귀 OLS
import numpy as np
import statsmodels.api as sm
from statsmodels.api import OLS
# 독립 변수(X)와 종속 변수(y) 분리
X = df[['size', 'rooms', 'floors', 'age']]
y = df['price']
# 상수항(절편)을 추가 (OLS에서는 상수항을 포함해야 함)
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
model.summary()
# rooms 컬럼의 회귀 계수
print(model.params['rooms'])
# pvalues
print(model.pvalues.max())
# R^2
model.rsquared
# 예측 수행 : 상수항 1 추가
predicted_price = model.predict([1, 175, 2, 2, 14])
print(predicted_price)3. scipy.stats 통계 모듈
import scipy.stats
from scipy.stats import ttest_rel, ttest_1samp, ttest_ind, f_oneway, wilcoxon, binom, chi2_contingency
# 대응 (쌍체) 표본 t-test : 치료 전 후
S, P = ttest_rel(df['후'], df['전'], alternative='')
# 단일표본 t-test
S, P = ttest_1samp(df, 기준값, alternative='')
# 독립표본 t-test
S, P = ttest_ind(df['A'], df['B'])
# ANOVA 2개이상 그룹
S, P = f_oneway(df['A'], df['B'], df['C'])
alternative에는 대립가설을 기준으로 큰값에는 greater, 작은값에는 less사용
# 윌콕슨 검정
med = 620
S, P = wilcoxon(df[''], med, alternative='')
# 이항 분포
n = 10 # 시행 횟수
p = 0.6 # 성공 확률
k = 6 # 성공 횟수
prob = binom.pmf(k, n, p) # P(X = k): 확률 질량 함수
prob = binom.cdf(k, n, p) # P(X <= k): 누적 분포 함수
prob = 1 - binom.cdf(k - 1, n, p) # P(X >= k)
# 교차표 및 카이제곱 검정
crosstab = pd.crosstab(df['범주1'], df['범주2'])
S, P, _, _ = chi2_contingency(crosstab)
# 출력
if P < 0.05:
print("귀무가설 기각: 통계적으로 유의미한 차이가 존재합니다.")
else:
print("귀무가설 채택: 통계적으로 유의미한 차이가 없습니다.")
4 일차 : 모의고사 풀어보기
데이터 마님의 모의고사 2~7회를 풀어보면서 모르는 부분은 필기를 해두었습니다.
또한, 퇴근후 딴짓의 작업형 3 예시문제들을 보면서 한번씩 따라해봤습니다.
시험 당일
평소 기출문제와 후기들을 보면 1유형이 가장 쉽다고 했지만, 9회차 실기 시험은 1유형이 가장 어려웠다는 후기가 많았습니다.
저도 1유형을 만만하게 생각해서 준비를 덜 했더니, 결국 1문제밖에 못 풀어서 아쉬웠습니다… ㅠㅠ
게다가 서버가 느려서 시험 전 30분동안 테스트 때도 코드 실행이 안되고,
(한 응시자분이 당황해서 "감독관님, print()가 안 돼요!!"라고 말씀하셨는데,
감독관님이 "프린트는 연결이 안 되어 있어요~"라고 답하셔서 빵 터졌습니다.ㅋㅋㅋㅋㅋ)
시험 시작 해서도 한 5분 넘게 코드가 안돌아서 결과가 출력되지 않았습니다.
다행히 고사장 10분 추가 시간을 배정해줬습니다.
저의 경험이 조금이라도 도움이 되길 바랍니다. 💪✨
다음은 제가 참고한 사이트와 블로그 입니다. 🙏🏻🙏🏻
<참고>
https://www.datamanim.com/dataset/03_dataq/index_big_python.html
1.빅데이터 분석기사 실기 (PYTHON) — DataManim
www.datamanim.com
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr
Big Data Certification KR
퇴근후딴짓 의 빅데이터 분석기사 실기 (Python, R tutorial code) 커뮤니티
www.kaggle.com
https://blog.naver.com/drdjmin/223485739258?
빅데이터 분석기사 실기 - 비전공자 3유형 야매로 벼락치기
보통 이 시험에서 3유형은 깊게 안 보는데 그래도 하루는 봐야겠어서 급하게 정리하는 3유형 공부법 1. 모...
blog.naver.com
빅데이터 분석기사 실기 3유형
독립성 검정 변수가 두개 이상 범주로 분할되어 있고, 독립적인지 연관성이 있는지 검정 귀무가설(H0) : 서로 독립 대립가설(H1) : 연관성이 있다 p-value < 0.05 이면 대립가설 채택 검정방법 순서 패
velog.io
'Certificate' 카테고리의 다른 글
| [SQLD] 54회 합격 후기 / 독학 / 공부법 / 1트 합격 / 일주일 (2) | 2024.09.19 |
|---|---|
| [오픽] 3일만에 AL 독학 후기 (22) | 2024.09.18 |
빅데이터 분석기사 9회 실기까지 합격했습니다!!
실기 시험은 변수가 너무 많고, 실수가 있을 수 도 있어서 성적 공개 2시간 전부터 엄청 긴장했습니다
엄청 두근 거리는 마음으로 4시에 결과를 확인했는데, 사전점수 합격이었습니다!!
빅분기 필기 합격 후에 실기 준비하기가 얼마나 귀찮던지... 이번 시험 보지 말까 고민도 했지만,
친구가 시험 보라고 보라고 엄청 설득해서 4일 전부터 공부를 시작했습니다.
|
|
빅분기 시험에 대한 소개나 기출 복기는 다른 분들이 잘 정리 해두셨으니
저는 제가 4일동안 어떻게 공부했는지 공유하겠습니다~!
<빅데이터 분석기사 4일 공부법>
Python을 어느 정도 사용할 수 있었기 때문에 2유형과 3유형에 집중했고, 1유형은 아예 패스했습니다.
(그래서 1유형은 1문제 밖에 못풀었습니다..ㅠㅠ)
1일차 : 2유형 공부하기
우선 데이터마님의 2유형 연습문제를 모두 풀고 저만의 코드를 정리해두었습니다.
분류 -> RandomForestClassifier, 회귀 -> RandomForestRegressor
혹시나 원-핫 인코딩 (get_dummies) 방식이 오류가 날까봐 LabelEncoder()도 준비를 했습니다.
랜포_분류
import pandas as pd
#데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/churnk/X_test.csv")
# 만약 데이터가 2개 주어지면
train = pd.read_csv('')
test = pd.read_csv('')
x_train = train.drop(['종속변수'])
y_train = train['종속변수']
x_test = test
x_train = x_train.drop(columns = ['CustomerId', 'Surname'])
y_train = y_train.drop(columns = ['CustomerId'])
x_test = x_test.drop(columns = ['CustomerId', 'Surname'])
import numpy as np
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, accuracy_score, recall_score
print(x_train.shape, y_train.shape, x_test.shape)
# category나 object 있는지 확인 > object 있음 > 인코딩 필요
total = pd.concat([x_train,x_test], axis = 0 )
# Object -> LabelEncoder
# total['Geography'] = LabelEncoder().fit_transform(total['Geography'])
# total['Gender'] = LabelEncoder().fit_transform(total['Gender'])
#변수처리(원핫 인코딩)
total = pd.get_dummies(total)
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
# 훈련/ 검증데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
# 학습
model = RandomForestClassifier()
model.fit(x_train, y_train) #학습
y_pred = model.predict(x_val) #예측
acc = accuracy_score(y_val, y_pred) #평가
f1 = f1_score(y_val, y_pred)
recall = recall_score(y_val, y_pred)
print(acc, f1, recall)
y_result = model.predict(x_test)
pd.DateFrame({'pred': y_result}).to_csv('result.csv', index = False)
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e3_p2_train_.csv')
test = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/krdatacertificate/e3_p2_test_.csv')
x_train = train.drop(columns = ['ID', 'TravelInsurance'])
y_train = train['TravelInsurance']
x_test = test.drop(columns = ['ID'])
import pandas as pd
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
total = pd.concat([x_train, x_test])
total = pd.get_dummies(total)
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_pred = model.predict_proba(x_val)[:,1]
auc = roc_auc_score(y_val, y_pred)
print(auc)
y_result = model.predict_proba(x_test)[:,1]
pd.DataFrame({'ID': test['ID'].values, 'proba': y_result}).to_csv('', index=False)
⭐️ 주의할 점 ⭐️
1. roc_auc_score을 구할때는 model.predict_proba(x_val)[:,1] 를 해야함
2. 다중분류일때 average='macro'
precision_score(y_true, y_pred, average='macro')
recall_score(y_true, y_pred, average='macro')
f1_score(y_true, y_pred, average='macro')3. 결과 제출할때 ID도 같이 제출해야 한다면 pd.DataFrame({'ID': test['ID'].values, 'proba': y_result}).to_csv('', index=False)
랜포_회귀
import pandas as pd
#데이터 로드
x_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/X_train.csv")
y_train = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/y_train.csv")
x_test= pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/studentscore/X_test.csv")
print(x_train.shape, y_train.shape, x_test.shape)
y_train.head()
x_train = x_train.drop(columns = ['StudentID'])
y_train = y_train['G3']
x_test = x_test.drop(columns = ['StudentID'])
print(x_train.shape, y_train.shape, x_test.shape)
total = pd.concat([x_train, x_test], axis = 0)
total.shape
total.info()
total = pd.get_dummies(total)
import numpy as np
import sklearn
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, mean_absolute_percentage_error
x_train = total.iloc[:len(x_train), :]
x_test = total.iloc[len(x_train):, :]
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size = 0.2, random_state = 111)
model = RandomForestRegressor()
model.fit(x_train, y_train)
y_pred = model.predict(x_val)
mae = mean_squared_error(y_val, y_pred)
rmse = np.sqrt(mean_squared_error(y_val, y_pred))
print(mae, rmse)
y_result = model.predict(x_test)
pd.DataFrame({'pred':y_result}).to_csv('/content/drive/MyDrive/빅분기/2유형_분류1.csv', index = False)
2 ,3 일차 : 3유형 공부하기
3유형은 따로 책이나 정보가 부족해서 블로그 후기들을 찾아봤습니다.
1. 로지스틱 회귀 Logit
import numpy as np
import statsmodels.api as sm
from statsmodels.api import Logit
df = df[['Survived', 'Sex', 'Age', 'SibSp', 'Parch']]
formula = 'Survived ~ Sex + Age + SibSp + Parch'
model = Logit.from_formula(formula, df).fit()
print(model.summary)
# Sex 가 범주형으로 하고 싶으면 C(Sex)로 바꾸면 됨
# 오즈비
odds_ratio = np.exp(model.params['Age'])
# 오즈비 5배 증가
odds_ratio = np.exp(model.params['Age'] * 5)
# 오차율
y_true = df['Survived']
y_pred_proba = model.predict(df)
y_pred =(y_pred_proba >= 0.5).astype(int) # 임계값 0.5를 기준으로 생존 여부 예측
error_rate = (y_pred != y_true).mean()
print(error_rate)
# 잔차 이탈도
residual_deviance = -2 * model.llf
# 로짓 우도
model.llf
# aic, bic
print(model.aic)
print(model.bic)
2. 선형회귀 OLS
import numpy as np
import statsmodels.api as sm
from statsmodels.api import OLS
# 독립 변수(X)와 종속 변수(y) 분리
X = df[['size', 'rooms', 'floors', 'age']]
y = df['price']
# 상수항(절편)을 추가 (OLS에서는 상수항을 포함해야 함)
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
model.summary()
# rooms 컬럼의 회귀 계수
print(model.params['rooms'])
# pvalues
print(model.pvalues.max())
# R^2
model.rsquared
# 예측 수행 : 상수항 1 추가
predicted_price = model.predict([1, 175, 2, 2, 14])
print(predicted_price)3. scipy.stats 통계 모듈
import scipy.stats
from scipy.stats import ttest_rel, ttest_1samp, ttest_ind, f_oneway, wilcoxon, binom, chi2_contingency
# 대응 (쌍체) 표본 t-test : 치료 전 후
S, P = ttest_rel(df['후'], df['전'], alternative='')
# 단일표본 t-test
S, P = ttest_1samp(df, 기준값, alternative='')
# 독립표본 t-test
S, P = ttest_ind(df['A'], df['B'])
# ANOVA 2개이상 그룹
S, P = f_oneway(df['A'], df['B'], df['C'])
alternative에는 대립가설을 기준으로 큰값에는 greater, 작은값에는 less사용
# 윌콕슨 검정
med = 620
S, P = wilcoxon(df[''], med, alternative='')
# 이항 분포
n = 10 # 시행 횟수
p = 0.6 # 성공 확률
k = 6 # 성공 횟수
prob = binom.pmf(k, n, p) # P(X = k): 확률 질량 함수
prob = binom.cdf(k, n, p) # P(X <= k): 누적 분포 함수
prob = 1 - binom.cdf(k - 1, n, p) # P(X >= k)
# 교차표 및 카이제곱 검정
crosstab = pd.crosstab(df['범주1'], df['범주2'])
S, P, _, _ = chi2_contingency(crosstab)
# 출력
if P < 0.05:
print("귀무가설 기각: 통계적으로 유의미한 차이가 존재합니다.")
else:
print("귀무가설 채택: 통계적으로 유의미한 차이가 없습니다.")
4 일차 : 모의고사 풀어보기
데이터 마님의 모의고사 2~7회를 풀어보면서 모르는 부분은 필기를 해두었습니다.
또한, 퇴근후 딴짓의 작업형 3 예시문제들을 보면서 한번씩 따라해봤습니다.
시험 당일
평소 기출문제와 후기들을 보면 1유형이 가장 쉽다고 했지만, 9회차 실기 시험은 1유형이 가장 어려웠다는 후기가 많았습니다.
저도 1유형을 만만하게 생각해서 준비를 덜 했더니, 결국 1문제밖에 못 풀어서 아쉬웠습니다… ㅠㅠ
게다가 서버가 느려서 시험 전 30분동안 테스트 때도 코드 실행이 안되고,
(한 응시자분이 당황해서 "감독관님, print()가 안 돼요!!"라고 말씀하셨는데,
감독관님이 "프린트는 연결이 안 되어 있어요~"라고 답하셔서 빵 터졌습니다.ㅋㅋㅋㅋㅋ)
시험 시작 해서도 한 5분 넘게 코드가 안돌아서 결과가 출력되지 않았습니다.
다행히 고사장 10분 추가 시간을 배정해줬습니다.
저의 경험이 조금이라도 도움이 되길 바랍니다. 💪✨
다음은 제가 참고한 사이트와 블로그 입니다. 🙏🏻🙏🏻
<참고>
https://www.datamanim.com/dataset/03_dataq/index_big_python.html
1.빅데이터 분석기사 실기 (PYTHON) — DataManim
www.datamanim.com
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr
Big Data Certification KR
퇴근후딴짓 의 빅데이터 분석기사 실기 (Python, R tutorial code) 커뮤니티
www.kaggle.com
https://blog.naver.com/drdjmin/223485739258?
빅데이터 분석기사 실기 - 비전공자 3유형 야매로 벼락치기
보통 이 시험에서 3유형은 깊게 안 보는데 그래도 하루는 봐야겠어서 급하게 정리하는 3유형 공부법 1. 모...
blog.naver.com
빅데이터 분석기사 실기 3유형
독립성 검정 변수가 두개 이상 범주로 분할되어 있고, 독립적인지 연관성이 있는지 검정 귀무가설(H0) : 서로 독립 대립가설(H1) : 연관성이 있다 p-value < 0.05 이면 대립가설 채택 검정방법 순서 패
velog.io
'Certificate' 카테고리의 다른 글
| [SQLD] 54회 합격 후기 / 독학 / 공부법 / 1트 합격 / 일주일 (2) | 2024.09.19 |
|---|---|
| [오픽] 3일만에 AL 독학 후기 (22) | 2024.09.18 |