
'데이터분석가 입문 Python 부트캠프ㅣ마케팅 데이터 매출 분석ㅣ제품 포트폴리오 데이터 시각화' 강의에 관한 글입니다.
데이터 시각화는 데이터 분석의 중요한 부분 중 하나입니다. 이 강의의 세 번째 챕터에서는 데이터 시각화의 기본 개념부터 고급 기법까지 폭넓게 다룹니다.
데이터 시각화 장점
이해력 향상
데이터를 시각적으로 표현함으로써 복잡한 정보를 보다 쉽게 이해할 수 있습니다. 수많은 숫자와 문자의 나열로 구성된 데이터는 그 자체로는 이해하기 어렵습니다. 하지만 이를 그래프나 차트로 시각화하면 데이터의 의미를 직관적으로 파악할 수 있습니다. 예를 들어, 막대 그래프나 원형 차트를 통해 각 데이터의 비율이나 양을 한눈에 볼 수 있어, 데이터의 본질을 보다 쉽게 이해할 수 있습니다.
패턴 및 트렌드 인식
그래프나 차트를 통해 데이터 내의 패턴과 트렌드를 쉽게 파악할 수 있습니다. 예를 들어, 시간에 따른 매출 변화를 선 그래프로 나타내면 계절적 요인이나 특정 이벤트와 연관된 매출 증가 혹은 감소 패턴을 쉽게 인식할 수 있습니다. 이는 데이터 분석가가 데이터 내 숨겨진 의미를 발견하고, 이를 바탕으로 유의미한 인사이트를 도출하는 데 큰 도움을 줍니다.
의사결정 지원
시각화된 데이터를 바탕으로 보다 정확하고 빠른 의사결정을 내릴 수 있습니다. 시각적 자료는 복잡한 데이터를 간결하게 전달하여, 의사결정자가 필요한 정보를 신속하게 이해하고 이에 따른 결정을 내릴 수 있도록 도와줍니다. 예를 들어, 경영진이 매출 데이터를 시각화한 보고서를 통해 특정 제품의 성과를 빠르게 파악하고, 이를 토대로 생산량 조정이나 마케팅 전략 변경 등의 결정을 내릴 수 있습니다.
본 강의에서는 Plotly Express 라이브러리를 사용하여 시각화를 하였습니다.
Bar 그래프
범주별 데이터 양이나 빈도를 나타낼 때 사용합니다. ex) 다른 제품 판매량 비교
import plotly.express as px
# 막대 그래프 생성
fig = px.bar(df
, x="col_1" # x축 데이터
, y="col_2" # y축 데이터
, color="col_3" # 막대 색상 구분, 'col_3' 값에 따라 달라짐
, title="title_name" # 그래프 제목 설정
, barmode='group' # 막대 표시 방식, 'group'은 나란히, 'stack'은 쌓아서 표시
)
# X축과 Y축 제목 설정 (선택적)
# fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 그래프 화면에 표시
fig.show()
- 예시 1)
# 예시 데이터 생성
import pandas as pd
data = {
'Month': ['January', 'February', 'March', 'January', 'February', 'March', 'January', 'February', 'March'],
'Sales': [20000, 24000, 30000, 15000, 16000, 22000, 180000, 26000, 27000],
'Ratio': [.234, .324, .3, .232, .1216, .332, .330, .330, .27],
'Region': ['North', 'North', 'North', 'South', 'South', 'South', 'East', 'East', 'East']
}
df1 = pd.DataFrame(data)
import plotly.express as px
fig = px.bar(df1
, x="Sales" # x축 데이터
, y="Month" # y축 데이터
, color="Region" # 막대 색상 구분, 'col_3' 값에 따라 달라짐
, title="Sales by Month" # 그래프 제목 설정
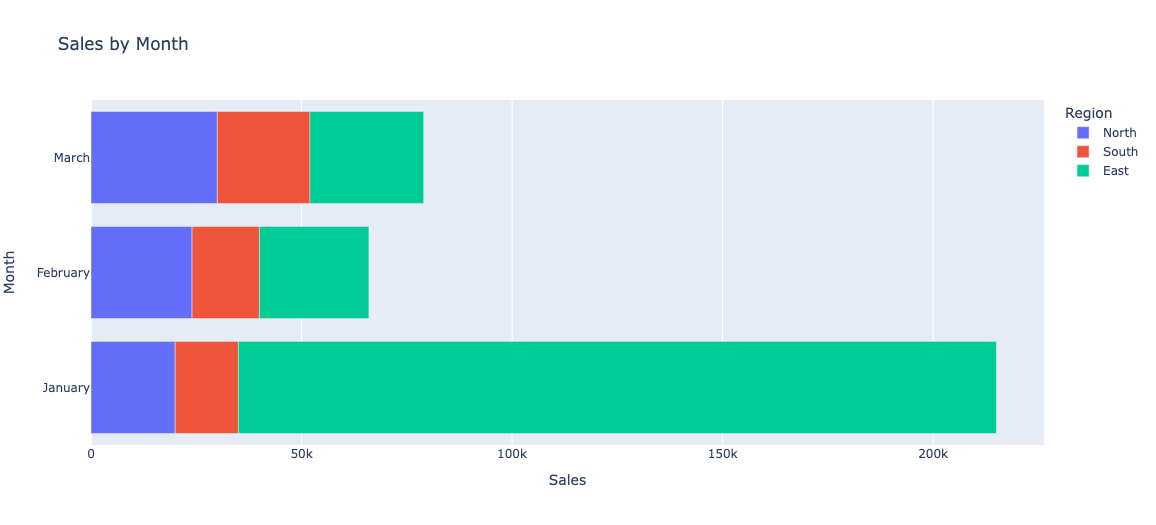
# , barmode='group' # 막대 표시 방식, 'group'은 나란히, 'stack'은 쌓아서 표시, stack 이 디폴트값
)
# X축과 Y축 제목 설정 (선택적)
# fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 그래프 화면에 표시
fig.show()# barmode 는 디폴드 값이 stack 방식임.
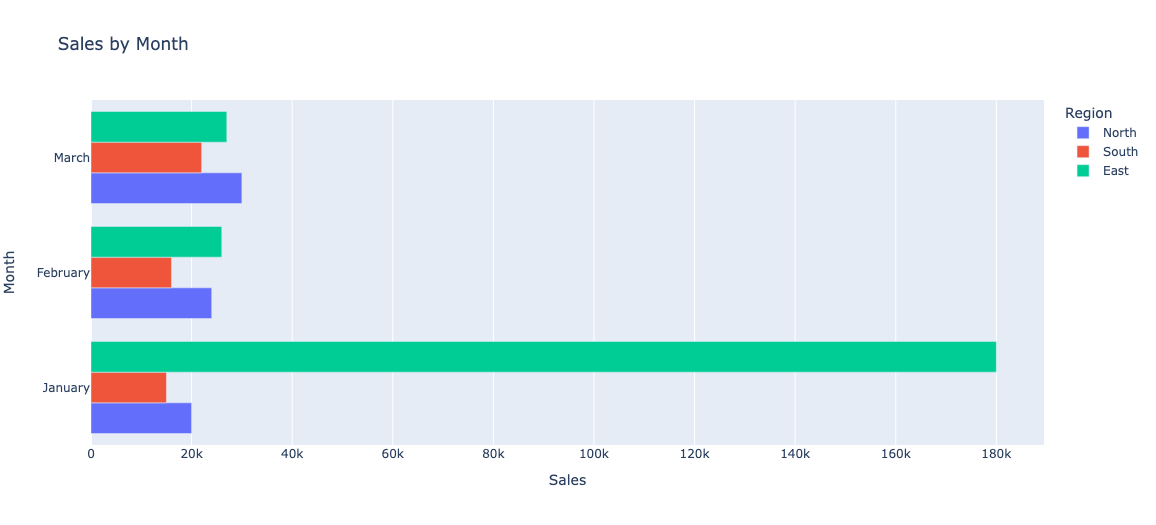
import plotly.express as px
fig = px.bar(df1
, x="Sales" # x축 데이터
, y="Month" # y축 데이터
, color="Region" # 막대 색상 구분, 'col_3' 값에 따라 달라짐
, title="Sales by Month" # 그래프 제목 설정
, barmode='group' # 막대 표시 방식, 'group'은 나란히, 'stack'은 쌓아서 표시
)
# X축과 Y축 제목 설정 (선택적)
# fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 그래프 화면에 표시
fig.show()# 위 그림과 달리 barmode를 group 으로 설정하여, 막대가 나란히.
hover_data() : 마우스를 특정 데이터 포인트 위로 가져갈 때 표시되는 추가 정보를 설정
hover_data = {
'col_1': True, # 'col_1'을 hover 데이터에 포함시키기
'col_2': ':.2f', # 'col_2'를 hover 데이터에 포함시키고, 소수점 아래 두 자리까지 표시
'col_3': ':.2s', # 'col_3'를 간결한 형식으로 표시 (예: 12345 -> "12.35K", 6789000 -> "6.79M")
'col_4': False # 'col_4'는 hover 데이터에 포함하지 않기
}
- 예제)
import pandas as pd
import numpy as np
import plotly.express as px
# 샘플 데이터 생성
np.random.seed(0)
months = ['January', 'February', 'March', 'April', 'May', 'June',
'July', 'August', 'September', 'October', 'November', 'December']
regions = ['North', 'South', 'East', 'West']
data = {# 이 코드는 이해하지 못하셔도 됩니다.
'Month': np.random.choice(months, 100, replace=True),
'Sales': np.random.randint(200, 1000, 100),
'Profit': np.random.randint(20, 100, 100),
'Region': np.random.choice(regions, 100, replace=True)
}
df = pd.DataFrame(data)
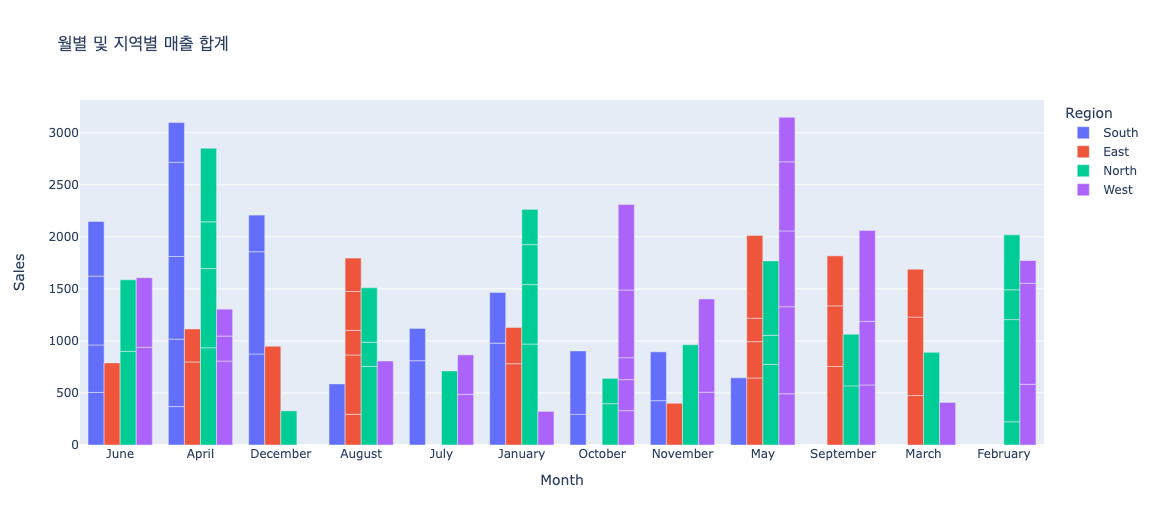
import plotly.express as px
# 막대 그래프 생성
fig = px.bar(df
, x="Month" # x축 데이터
, y="Sales" # y축 데이터
, color="Region" # 막대 색상 구분, 'col_3' 값에 따라 달라짐
, title="월별 및 지역별 매출 합계" # 그래프 제목 설정
, barmode='group' # 막대 표시 방식, 'group'은 나란히, 'stack'은 쌓아서 표시
, hover_data = {
'Region': False, # 'Region'을 hover 데이터에 제거
'Profit_Margin': ':.2f', # 'Profit_Margin'를 hover 데이터에 포함시키고, 소수점 아래 두 자리까지 표시
}
)
# X축과 Y축 제목 설정 (선택적)
# fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 그래프 화면에 표시
fig.show()
Line 그래프
시간에 따른 데이터의 변화나 추세를 나타낼 때 사용. ex) 시간에 따른 주식 가격 변동이나 기온 변화를 보여주기 좋음.
import plotly.express as px
# 선 그래프 생성
line_fig = px.line(df
, x="col_1" # X축에 표시할 컬럼
, y="col_2" # Y축에 표시할 컬럼
, color="col_3" # 각 선의 색상을 구분하기 위한 컬럼
, facet_col="col_4" # 서브플롯을 구분하기 위한 컬럼 (세로로 나누기)
# facet_row="col_5"를 사용하면 가로로 나눌 수 있음
, title="title_name" # 그래프의 제목
)
# line_fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 선 그래프 표시
line_fig.show()
- 예시 ) 각 거래에 대한 날짜, 금액, 결제 수단, 카테고리를 포함한 가상의 거래 데이터
결제 수단이 'Card'이거나 카테고리가 'A'인 경우, 금액이 각각 3배, 2.3배로 조정
import numpy as np
import pandas as pd
data_size = 1000
np.random.seed(0)
dates = pd.date_range('2021-01-01', '2021-01-31')
random_dates = np.random.choice(dates, size=data_size)
random_dates.sort()
# 데이터 생성
data = {
'tras_id': np.arange(data_size), # 순차적인 번호를 tras_id로 사용
'date': random_dates,
'amount': np.random.randint(100, 1000, size=data_size),
'payment': np.random.choice(['Cash', 'Card'], size=data_size),
'category': np.random.choice(['A', 'B'], size=data_size)
}
df = pd.DataFrame(data)
df['amount'] = df.apply(lambda row: row['amount'] * 3 if row['payment'] == 'Card' else row['amount'], axis=1)
df['amount'] = df.apply(lambda row: row['amount'] * 2.3 if row['category'] == 'A' else row['amount'], axis=1)
df.head()
# date: 날짜 데이터로, 특정 기간(2021년 1월) 동안의 일자별 데이터를 나타냅니다.
# amount: 수치형 데이터로, 각 날짜에 해당하는 금액(거래, 판매 등)을 나타냅니다.
# payment: 범주형 데이터로, 거래의 결제 방식(현금 또는 카드)을 나타냅니다.
# tras_id: 각 행의 고유 식별자로, 거래나 이벤트를 구별하는 데 사용됩니다.
# 각 날짜별로 총 거래 금액을 시각화함 (i.e. 'date' 별 'amount'의 합)
df_agg1 = df.groupby(by = 'date')['amount'].sum().reset_index()
df_agg1
import plotly.express as px
# 선 그래프 생성
line_fig = px.line(df_agg1
, x="date" # X축에 표시할 컬럼
, y="amount" # Y축에 표시할 컬럼
# , color="col_3" # 각 선의 색상을 구분하기 위한 컬럼
# , facet_col="col_4" # 서브플롯을 구분하기 위한 컬럼 (세로로 나누기)
# # facet_row="col_5"를 사용하면 가로로 나눌 수 있음
# , title="title_name" # 그래프의 제목
)
# line_fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 선 그래프 표시
line_fig.show()

# 각 날짜와 결제수단 별로 총 거래 금액을 시각화함 (i.e. 'date' & 'payment' 별 'amount'의 합)
df_agg2 = df.groupby(by = ['date', 'payment'])['amount'].sum().reset_index()
df_agg2
import plotly.express as px
# 선 그래프 생성
line_fig = px.line(df_agg2
, x="date" # X축에 표시할 컬럼
, y="amount" # Y축에 표시할 컬럼
, color="payment" # 각 선의 색상을 구분하기 위한 컬럼
# , facet_col="col_4" # 서브플롯을 구분하기 위한 컬럼 (세로로 나누기)
# # facet_row="col_5"를 사용하면 가로로 나눌 수 있음
# , title="title_name" # 그래프의 제목
)
# line_fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 선 그래프 표시
line_fig.show()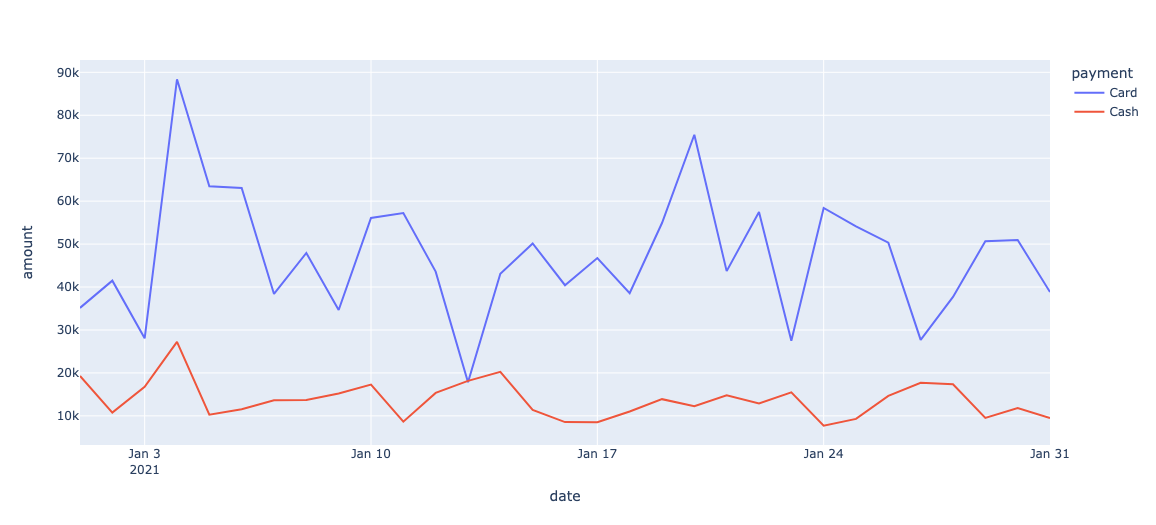
facet_col/ row
열/ 행의 고유 값마다 별도의 그래프 생성함.
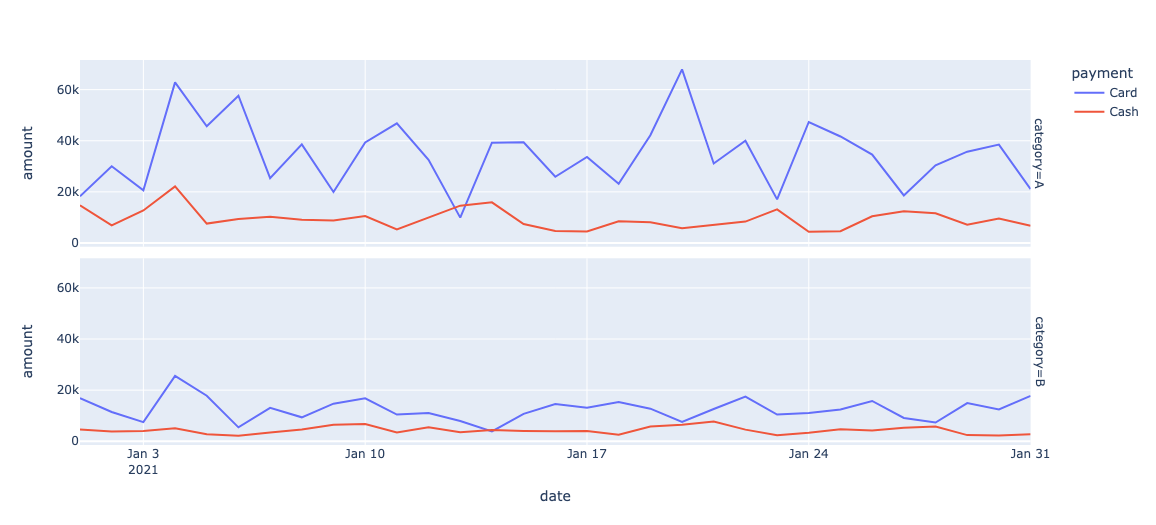
# 각 날짜, 결제수단, 카테고리 별로 총 거래 금액을 시각화함 (i.e. 'date' & 'payment' & 'category'별 'amount'의 합)
df_agg3 = df.groupby(by = ['date', 'payment', 'category'])['amount'].sum().reset_index()
df_agg3
import plotly.express as px
# 선 그래프 생성
line_fig = px.line(df_agg3
, x="date" # X축에 표시할 컬럼
, y="amount" # Y축에 표시할 컬럼
, color="payment" # 각 선의 색상을 구분하기 위한 컬럼
# , facet_col="category" # 서브플롯을 구분하기 위한 컬럼 (세로로 나누기)
, facet_row="category" #를 사용하면 가로로 나눌 수 있음
# , title="title_name" # 그래프의 제목
, hover_data = {
'category': True, # 'col_1'을 hover 데이터에 포함시키기
}
)
# line_fig.update_layout(xaxis_title="x_title_name", yaxis_title="y_title_name")
# 선 그래프 표시
line_fig.show()
# facet_row를 추가 하여, 'Category' 마다 다른 그래프를 생성함.
Histogram
데이터의 분포를 시각적으로 나타낼 때 사용함. ex) 고객 연령대 분포, 제품 가격대 분포 등 데이터의 빈도수를 보여주는데 적합함.
import plotly.express as px
# 히스토그램 생성
fig = px.histogram(
df, # 사용할 데이터셋
x='col_1', # x축에 사용할 열 이름
color='col_2', # 색상으로 구분할 카테고리 열 이름
barmode='stack/overlay/group', # 막대 모드 설정 (group/overlay/stack 중 선택)
marginal="rug", # margin에 추가적인 데이터 포인트 분포 표시
title='histogram', # 히스토그램의 제목
# nbins= 10 # 막대의 개수
)
# 히스토그램 표시
fig.show()
- 예시 )
import seaborn as sns
iris = sns.load_dataset('iris')
import plotly.express as px
# 히스토그램 생성
fig = px.histogram(
iris, # 사용할 데이터셋
x='sepal_length', # x축에 사용할 열 이름
color='species', # 색상으로 구분할 카테고리 열 이름
barmode='overlay', # 막대 모드 설정 (group/overlay/stack 중 선택)
marginal="rug", # margin에 추가적인 데이터 포인트 분포 표시
# title='histogram', # 히스토그램의 제목
nbins= 30 # 막대의 개수
)
# 히스토그램 표시
fig.show()
# 히스토그램 생성시 Overlay로 설정하면 두 개 이상의 데이터 세트의 분포를 비교하기 쉬움.

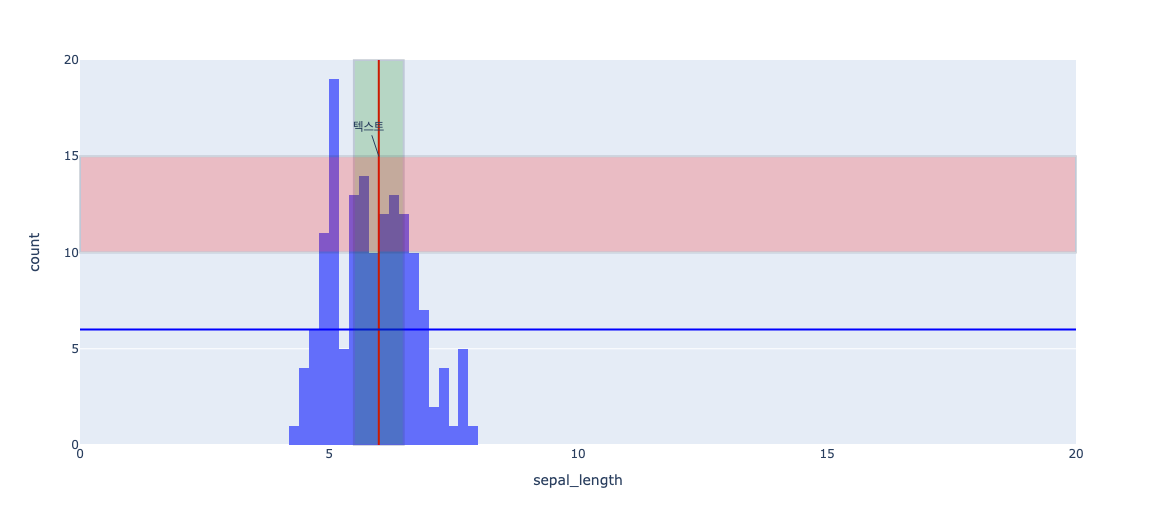
add_vline/vrect/annotation, update_xaxes
# 세로선 추가
fig.add_vline(
x=20, # 세로선의 x축 위치
line_color="red/blue/green" # 선의 색상
)
# 가로선 추가
fig.add_hline(
y=20, # 가로선의 y축 위치
line_color="red/blue/green" # 선의 색상
)
# 주석 추가
fig.add_annotation(
x=20 , # 주석의 x축 위치
y=30 , # 주석의 y축 위치
text="텍스트" # 표시할 텍스트
)
# 세로 스팬 추가
fig.add_vrect(
x0='20', # 스팬의 시작 x축 위치
x1='2019-03-15', # 스팬의 종료 x축 위치
fillcolor="red/blue/green", # 스팬의 색상
opacity=0.5, # 스팬의 불투명도
)
# x축 범위 설정 (예: 0부터 20까지)
fig.update_xaxes(range=[0, 20])
# y축 범위 설정 (예: -5부터 5까지)
import plotly.express as px
# 히스토그램 생성
fig = px.histogram(
iris, # 사용할 데이터셋
x='sepal_length', # x축에 사용할 열 이름
# color='species', # 색상으로 구분할 카테고리 열 이름
# barmode='overlay', # 막대 모드 설정 (group/overlay/stack 중 선택)
# marginal="rug", # margin에 추가적인 데이터 포인트 분포 표시
# title='histogram', # 히스토그램의 제목
nbins= 30 # 막대의 개수
)
# 세로선 추가
fig.add_vline(
x=6, # 세로선의 x축 위치
line_color="red" # 선의 색상
)
# 가로선 추가
fig.add_hline(
y=6, # 가로선의 y축 위치
line_color="blue" # 선의 색상
)
# 주석 추가
fig.add_annotation(
x=6 , # 주석의 x축 위치
y=15 , # 주석의 y축 위치
text="텍스트" # 표시할 텍스트
)
# 세로 스팬 추가
fig.add_vrect(
x0='5.5', # 스팬의 시작 x축 위치
x1='6.5', # 스팬의 종료 x축 위치
fillcolor="green", # 스팬의 색상
opacity=0.2, # 스팬의 불투명도
)
#가로 스팬 추가
fig.add_hrect(
y0='10', # 스팬의 시작 y축 위치
y1='15', # 스팬의 종료 y축 위치
fillcolor="red", # 스팬의 색상
opacity=0.2, # 스팬의 불투명도
)
# x축 범위 설정 (예: 0부터 20까지)
fig.update_xaxes(range=[0, 20])
# y축 범위 설정 (예: -5부터 5까지)
fig.update_yaxes(range=[0, 20])
# 히스토그램 표시
fig.show()
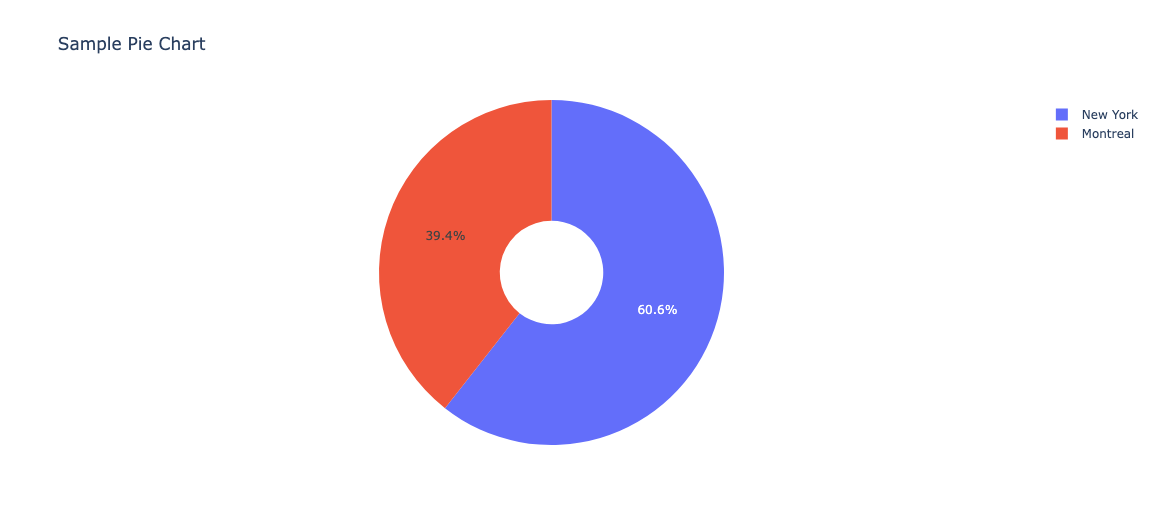
Pie 그래프
각 부분의 비율을 시각적으로 보여주는 차트
px.pie() 함수는 제공된 데이터에서 자동으로 값을 합산하고, 이를 전체에 대한 비율로 변환
import plotly.express as px
import pandas as pd
# px.pie() 함수를 사용하여 파이 차트 생성
fig = px.pie(
df, # 데이터 프레임
names='col_1', # 파이 차트의 각 부분을 구별하는 열
values='col_2', # 각 부분의 크기를 결정하는 열
title='Sample Pie Chart', # 차트 제목
hole=0.3 # 중앙의 빈 공간 크기 (0에서 1 사이의 값)
)
# 차트 표시
fig.show()
import pandas as pd
import plotly.express as px
# 예시 데이터 생성
data = {
'Fruit': ['Apples', 'Oranges', 'Bananas', 'Apples', 'Oranges', 'Bananas'],
'Amount': [50, 31, 42, 17, 36, 27],
'City': ['New York', 'New York', 'New York', 'Montreal', 'Montreal', 'Montreal']
}
df = pd.DataFrame(data)
import plotly.express as px
import pandas as pd
# px.pie() 함수를 사용하여 파이 차트 생성
fig = px.pie(df, # 데이터 프레임
names='City', # 파이 차트의 각 부분을 구별하는 열
values='Amount', # 각 부분의 크기를 결정하는 열
title='Sample Pie Chart', # 차트 제목
hole=0.3 # 중앙의 빈 공간 크기 (0에서 1 사이의 값)
)
# 차트 표시
fig.show()
Strip
개별 데이터 포인트를 배치하여 데이터 분포와 개별 값의 분포를 시각적으로 표현
import plotly.express as px
import pandas as pd
# px.strip() 함수를 사용하여 스트립 플롯 생성
fig = px.strip(
df, # 데이터 프레임
x='Category', # x축에 표시될 데이터 열의 이름
y='Value', # y축에 표시될 데이터 열의 이름
color = 'red/green/blue' #color
title='Sample Strip Plot' # 차트 제목
)
# 차트 표시
fig.show()
-예시 )
import pandas as pd
import numpy as np
import plotly.express as px
np.random.seed(2)
df = pd.DataFrame( {"value": [1,1,1,1,1,1,1,1,1,
2,2,2,2,2,2,
3,3,3,3,
4,4,4,
5,5,
6,
7,
]})
df['category'] = 'Regular'
df.at[len(df) - 1, 'category'] = 'Last' # 마지막 데이터에 대한 표시
df['random'] = np.random.randn( len(df))
fig = px.scatter(df, y='random', x='value', color='category', title='Strip-like Chart Using Scatter', width = 500,height = 300)
fig.update_yaxes(range =[-10,10])
df.loc[df.index[-1], 'Category'] = 'Different Color'
fig.update_traces(marker=dict(size=10, opacity=0.5), selector=dict(mode='markers'))
fig2 = px.histogram(df , x = 'value', color = 'category', width = 500,height = 300, nbins = len(df) )
fig.show()
fig2.show()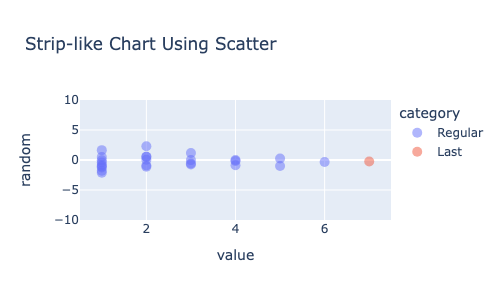

import seaborn as sns
iris = sns.load_dataset('iris')
import plotly.express as px
import pandas as pd
# px.strip() 함수를 사용하여 스트립 플롯 생성
fig = px.strip(
iris, # 데이터 프레임
x='species', # x축에 표시될 데이터 열의 이름
y='sepal_length', # y축에 표시될 데이터 열의 이름
color = 'species', #color
title='Sample Strip Plot' # 차트 제목
)
# 차트 표시
fig.show()

Scatter
x축: 한 수치형 변수의 값을 나타냄.
y축: 다른 수치형 변수의 값을 나타냄.
산점도의 목적: x축과 y축에 표시된 두 변수 간의 관계를 시각적으로 표현.
import plotly.express as px
# px.scatter 함수를 사용하여 산점도 생성
fig = px.scatter(
df,
x="col_1", # x축에 표시될 데이터 열
y="col_2", # y축에 표시될 데이터 열
color="col_3", # 데이터 포인트의 색상을 구분할 범주형 데이터 열
opacity = .6 # 투명도
marginal_y="rug", # y축에 박스 플롯 추가
marginal_x="rug", # x축에 박스 플롯 추가
title="name" # 차트 제목
)
# 차트 표시
fig.show()
import seaborn as sns
iris = sns.load_dataset('iris')
import plotly.express as px
# px.scatter 함수를 사용하여 산점도 생성
fig = px.scatter(
iris,
x="sepal_length", # x축에 표시될 데이터 열
y="sepal_width", # y축에 표시될 데이터 열
color="species", # 데이터 포인트의 색상을 구분할 범주형 데이터 열
opacity = .6, # 투명도
marginal_y="rug", # y축에 박스 플롯 추가
marginal_x="rug", # x축에 박스 플롯 추가
title="sepal" # 차트 제목
)
# 차트 표시
fig.show()
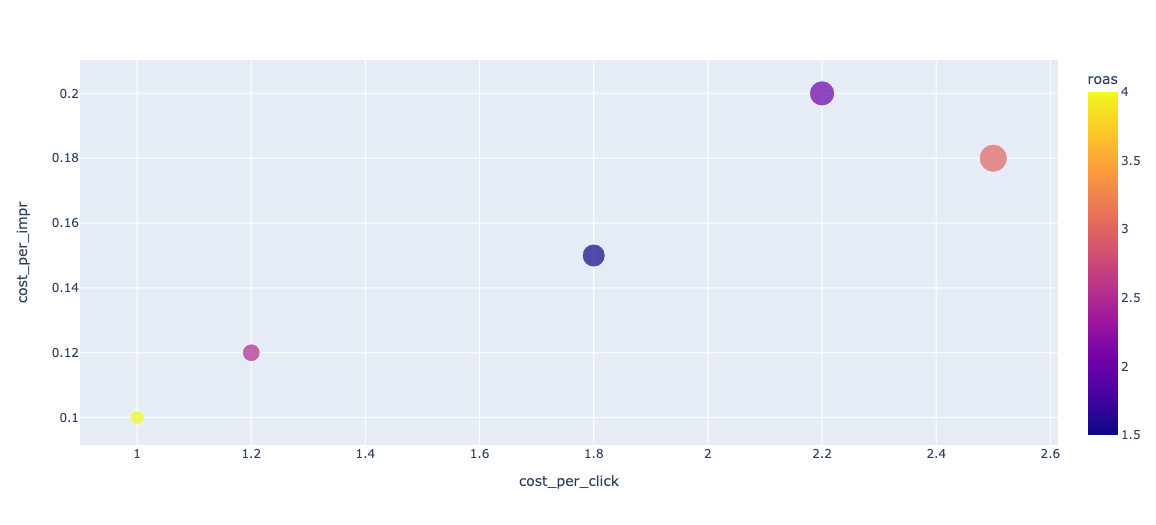
Bubble chart (2개 이상 상관관계)
데이터 포인트의 두 가지 수치 값을 축으로 하고, 추가 변수의 크기와 색상을 사용하여 다차원적인 데이터 관계를 시각화
import pandas as pd
import plotly.express as px
# 직접 입력된 가상의 광고 캠페인 데이터
data = {
'campaign': [
'Campaign A', 'Campaign B', 'Campaign C', 'Campaign D', 'Campaign E'
],
'cost_per_click': [
1.20, 2.50, 1.80, 1.00, 2.20
],
'cost_per_impr': [
0.12, 0.18, 0.15, 0.10, 0.20
],
'monthly_cost': [
3000, 7500, 5000, 2000, 6000
],
'roas': [
2.5, 3.0, 1.5, 4.0, 2.0
]
}
# 데이터 프레임 생성
df_campaigns = pd.DataFrame(data)
df_campaigns
import plotly.express as px
# px.scatter 함수를 사용하여 산점도 생성
fig = px.scatter(
df_campaigns,
x="cost_per_click", # x축에 표시될 데이터 열
y="cost_per_impr", # y축에 표시될 데이터 열
size = 'monthly_cost',
color = 'roas',
hover_name = 'campaign'
)
# 차트 표시
fig.show()
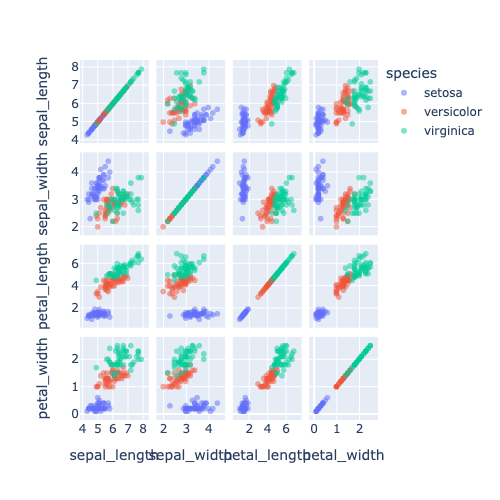
px.scatter_matrix()
특성 간의 모든 쌍에 대한 산점도를 표시
import plotly.express as px
fig = px.scatter_matrix(df,
dimensions=["col_1", "col_2"], # 주로 numeric
color="col_3", # 주로 categorical
opacity=0.5 # 투명도를 50%
)
fig.show()
import seaborn as sns
iris = sns.load_dataset('iris')
import plotly.express as px
fig = px.scatter_matrix(iris,
dimensions=["sepal_length", "sepal_width", "petal_length", 'petal_width'], # 주로 numeric
color="species", # 주로 categorical
opacity=0.5, # 투명도를 50%
height = 500,
width = 500
)
fig.show()
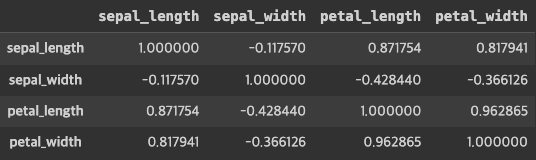
iris[["sepal_length", "sepal_width", "petal_length", 'petal_width']].corr()
- 예시 1) 펭귄의 종(species)에 따라 색상 구분
import pandas as pd
import seaborn as sns
df = sns.load_dataset('penguins')
import plotly.express as px
# px.scatter 함수를 사용하여 산점도 생성
fig = px.scatter(
df,
x="bill_length_mm", # x축에 표시될 데이터 열
y="body_mass_g", # y축에 표시될 데이터 열
color = 'species',
)
# 차트 표시
fig.show()

- 예시 2) 성별(sex) 로 색상 구분
import plotly.express as px
fig = px.scatter_matrix(df,
dimensions=["bill_length_mm", "bill_depth_mm", "flipper_length_mm", 'body_mass_g'], # 주로 numeric
color="sex", # 주로 categorical
opacity=0.5, # 투명도를 50%
height = 500,
width = 500
)
fig.show()

데이터 시각화는 데이터를 보다 명확하게 이해하고, 중요한 패턴과 트렌드를 인식하며, 신속하고 정확한 의사결정을 내리는 데 있어 매우 중요한 역할을 합니다. 따라서 데이터 분석가뿐만 아니라 다양한 분야의 전문가들이 데이터 시각화를 효과적으로 활용하는 것이 중요합니다.
후기 및 추천 : 오늘 강의에서는 데이터 시각화 대해 공부하였습니다. 자세하게 설명해 주시기 때문에 입문자도 잘 이해할 수 있는 강의입니다!
'Data Analytics > Online Course' 카테고리의 다른 글
| [메타코드 강의 후기] Python 데이터분석 | 파이썬 기초 (0) | 2024.07.02 |
|---|---|
| [강의 후기] 파이썬 데이터 분석 | 제품 포트폴리오 분석 (0) | 2024.06.30 |
| [특강 후기] 데이터 분석가 현직자 특강 후기 (0) | 2024.06.28 |
| [강의 후기] 파이썬 데이터 분석 | 데이터 전처리 (0) | 2024.06.22 |
| [강의 후기] 파이썬 데이터 분석 | 파이썬 기초 (0) | 2024.06.20 |