
이번에 소개할 강의는 '공공데이터로 Python 데이터분석' 강의입니다. 본 강의는 크게 두 가지 파트로 구성되어 있습니다. 첫 번째는 데이터 분석을 위한 파이썬 기초이며, 두 번째는 데이터 분석 및 시각화입니다.
지난번 글에 이어서 "데이터 분석 및 시각화"에 대해 다루겠습니다. 이번 글에서는 파이썬을 사용한 데이터 분석의 예를 통해 공공데이터를 활용하여 분석하고 시각화하는 방법을 소개합니다.
메타코드M
AI 강의 & 커뮤니티 플랫폼ㅣ300만 조회수 기록한 IT 현직자들의 교육과 함께 하세요
www.metacodes.co.kr
데이터 관련 프로젝트를 할때는 좋은 품질의 데이터를 확보하는 것이 중요합니다. 1. 구축된 데이터를 확보하는것과, 2. 데이터 크롤링이 있습니다.
먼저, 1번을 위해서는 데이터 저작권과 활용 가능 범위를 확인 하는 것이 중요합니다.

대한민국 공식 정부 홈페이지 공공데이터 포털로는 https://www.data.go.kr/ 이 있습니다.
데이터 로드
import pandas as pd
df = pd.read_csv('소방청_구조활동현황_20211231.csv', encoding = 'cp949')
# 데이터 확인
# 1. 상위 5개
df.head()
# 2. 랜덤하게 3개, 시드값
df.sample(3, random_state = 24)
# 3. 하위 5개
df.tail()
데이터 전처리
날짜 및 시간 데이터를 datetime 타입으로 변환하여 시간 계산 및 비교를 용이하게 합니다.
df.info()
# object --> datetime
df['신고년월일'] = pd.to_datetime(df['신고년월일'])
df['출동년월일'] = pd.to_datetime(df['출동년월일'])
df['신고시각'] = pd.to_datetime(df['신고시각'], format='%H:%M')
df['출동시각'] = pd.to_datetime(df['출동시각'], format='%H:%M')
신고일시 및 출동일시 컬럼을 생성하여 시간 관련 데이터를 통합 관리할 수 있게 합니다.
# 문자열 형식으로 다시 변환
df['신고년월일'] = df['신고년월일'].astype(str)
df['출동년월일'] = df['출동년월일'].astype(str)
df['신고시각'] = df['신고시각'].dt.strftime('%H:%M')
df['출동시각'] = df['출동시각'].dt.strftime('%H:%M')
# 신고일시 및 출동일시 컬럼 생성
df['신고일시'] = pd.to_datetime(df['신고년월일'] + ' ' + df['신고시각'])
df['출동일시'] = pd.to_datetime(df['출동년월일'] + ' ' + df['출동시각'])
# 최종 데이터 정보 확인
df.info()
불필요한 컬럼을 삭제하고, 결측치를 특정 값으로 대체하거나 삭제하여 데이터를 정리합니다.
# 불필요한 컬럼 삭제
df_new = df.drop(['신고년월일', '신고시각', '출동년월일', '출동시각'], axis=1)
# 결측치 확인 및 처리
df_new.isna().sum()
# 특정 컬럼의 결측치를 특정 값으로 대체
df_new['발생장소_구'].fillna('세종특별자치시', inplace=True)
# 특정 데이터 필터링 및 삭제
to_drop = (df_new['발생장소_구'] == '경기도') | (df_new['발생장소_구'] == '경상남도')
df_new = df_new[~to_drop]
데이터를 그룹화하여 사고 발생 건수를 집계하고, 피벗 테이블을 생성하여 데이터를 재구성합니다.
# 데이터 그룹화 및 집계
df_new.groupby('발생장소_구')['번호'].count()
# 이중 그룹화 및 집계
double_grouped = df_new.groupby(['발생장소_시', '발생장소_구'])['번호'].count()
df_double = pd.DataFrame(double_grouped).reset_index()
df_double = df_double.rename(columns={'번호': '사고발생건수'})
# 피벗 테이블 생성
df_bouble_pivot = pd.pivot_table(df_new, index=['발생장소_시', '발생장소_구'], aggfunc='size').reset_index(name='사고발생건수')
# 결과 출력
df_bouble_pivot데이터 시각화
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
plt.rcParams['font.family'] = 'AppleGothic'
plt.figure(figsize = (20,5))
sns.barplot(data = df_bouble_pivot, x = '발생장소_시', y = '사고발생건수', hue = '발생장소_시')
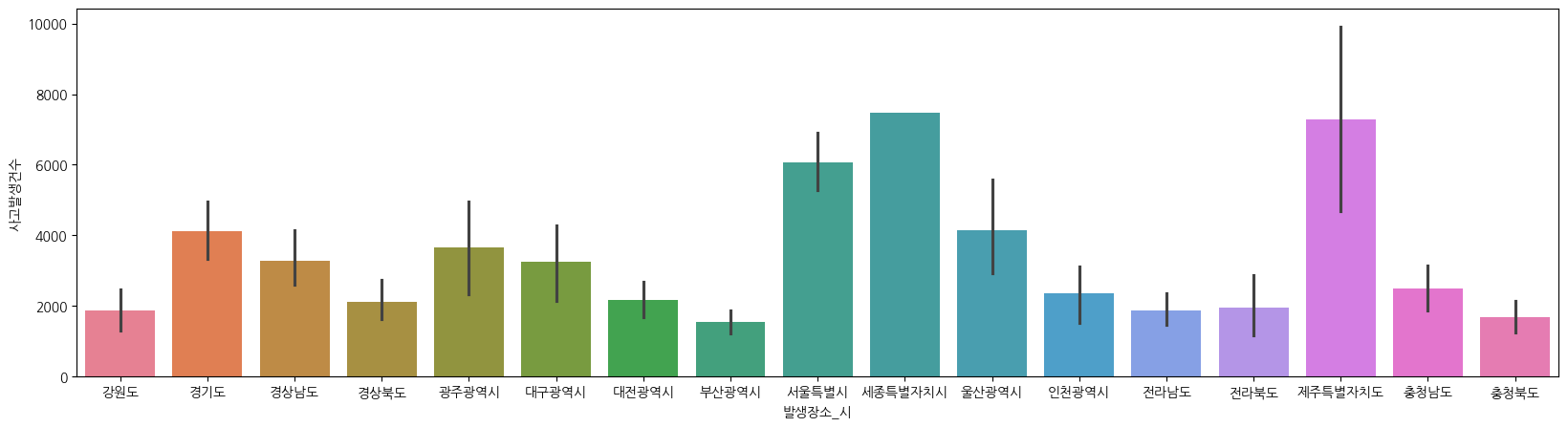
df_seoul = df_seoul[df_seoul['발생장소_구'] != df_seoul['발생장소_시']]
df_seoul_pivot = df_seoul.pivot_table(index = ['발생장소_구'], aggfunc = 'size').reset_index(name = '사고발생건수')
plt.figure(figsize = (20,5))
ax = sns.barplot(df_seoul_pivot, x = '발생장소_구', y = '사고발생건수', hue = '발생장소_구')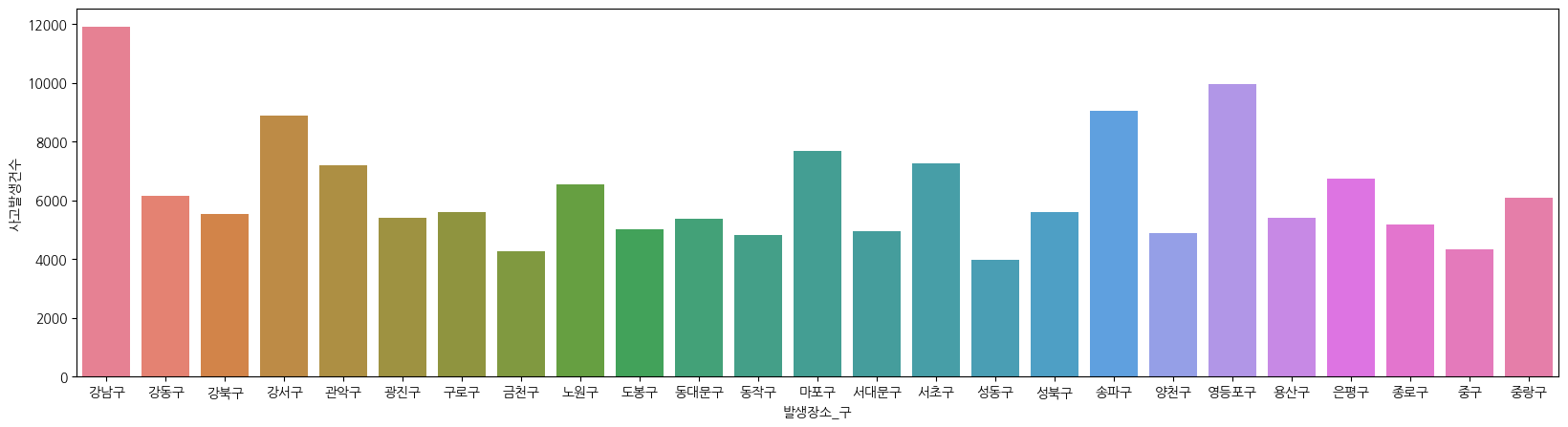
plt.figure(figsize = (20,5))
sns.lineplot(data= df_seoul_pivot, x = '발생장소_구', y = '사고발생건수')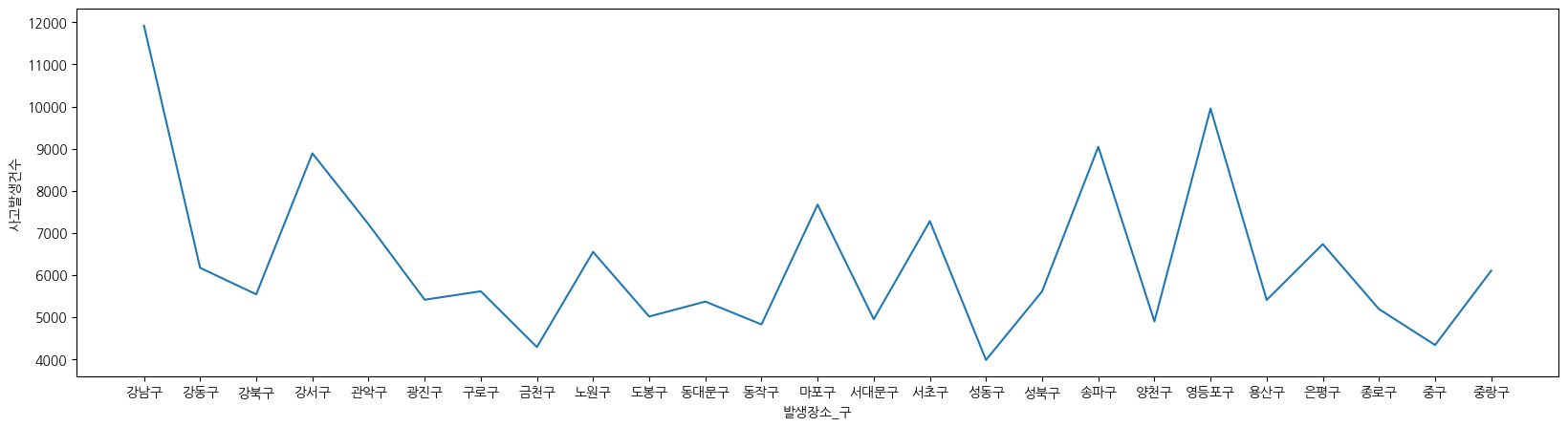
df_date_pivot['신고일시'] = pd.to_datetime(df_date_pivot['신고일시']).dt.date
plt.figure(figsize = (20,5))
sns.lineplot(data= df_date_pivot, x = '신고일시', y = '사고발생건수', hue = '발생장소_구')
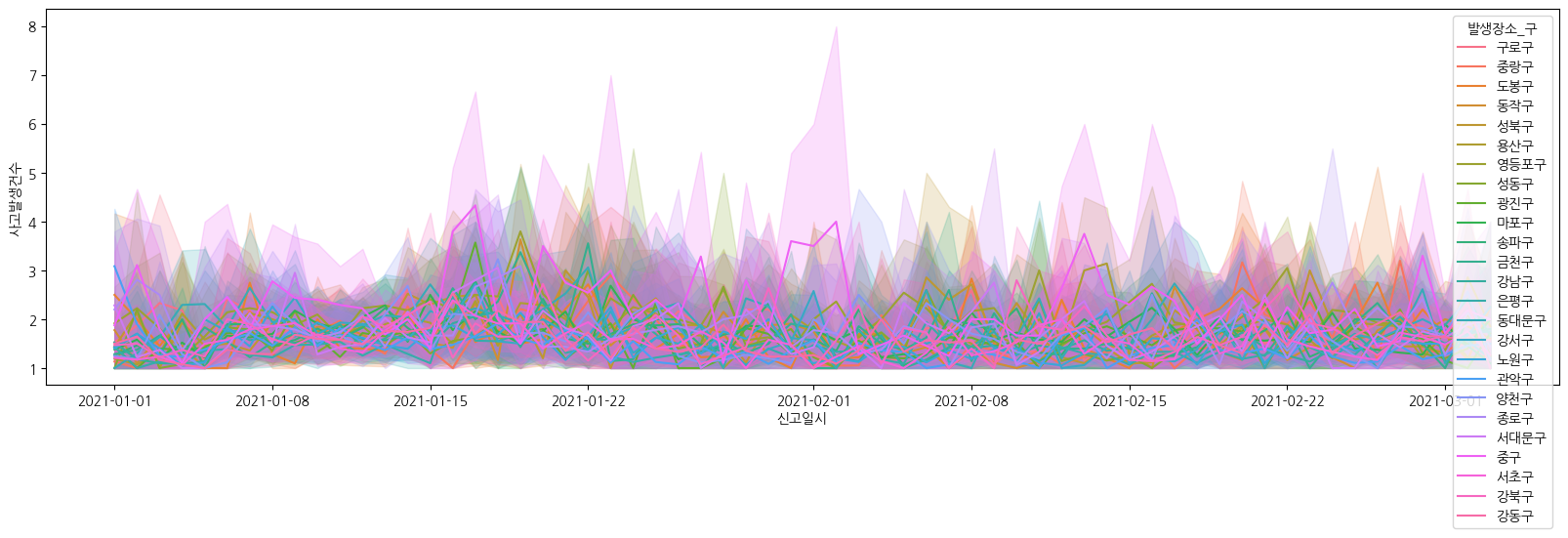
출동 소요시간 분석
소요시간 계산 및 탐색
# 출동 소요시간 계산
df['출동소요시간'] = (df['출동일시'] - df['신고일시'])
df['출동소요시간_초'] = df['출동소요시간'].dt.total_seconds().astype(int)
df['출동소요시간_분'] = (df['출동소요시간_초'] / 60).astype(int)
# 출동 소요시간 이상치 제거
df = df[~(df['신고일시'] > df['출동일시'])]
소요시간 시각화
# 박스플롯을 통한 소요시간 시각화
plt.figure(figsize=(20, 5))
sns.boxplot(data=df, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
plt.show()
# 소요시간 분포 및 이상치 제거 후 시각화
mean = df['출동소요시간_분'].mean()
std = df['출동소요시간_분'].std()
threshold = mean + 3 * std
df_cleaned = df[df['출동소요시간_분'] <= threshold]
plt.figure(figsize=(20, 5))
sns.boxplot(data=df_cleaned, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
plt.show()
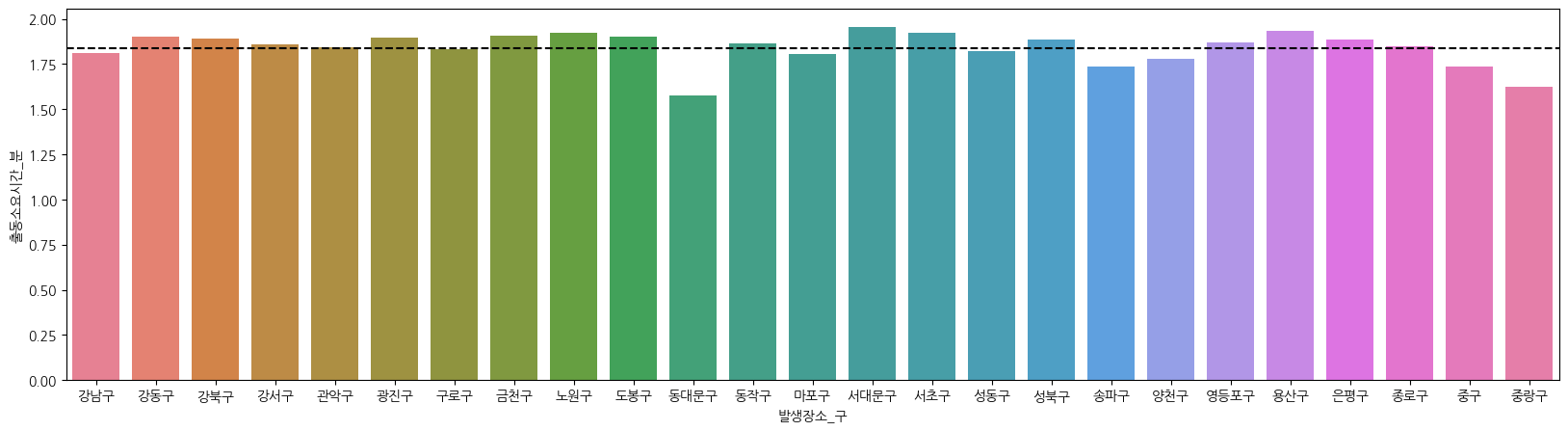
# 구별 평균 출동 소요시간 바플롯 시각화
df_cleaned_pivot = df_cleaned.pivot_table(index='발생장소_구', values='출동소요시간_분', aggfunc='mean').reset_index()
plt.figure(figsize=(20, 5))
sns.barplot(data=df_cleaned_pivot, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
# 서울시 평균 소요시간 선 추가
mean_time = df_cleaned_pivot['출동소요시간_분'].mean()
plt.axhline(mean_time, color='black', linestyle='--', label='평균 출동 소요 시간')
plt.legend()
plt.show()
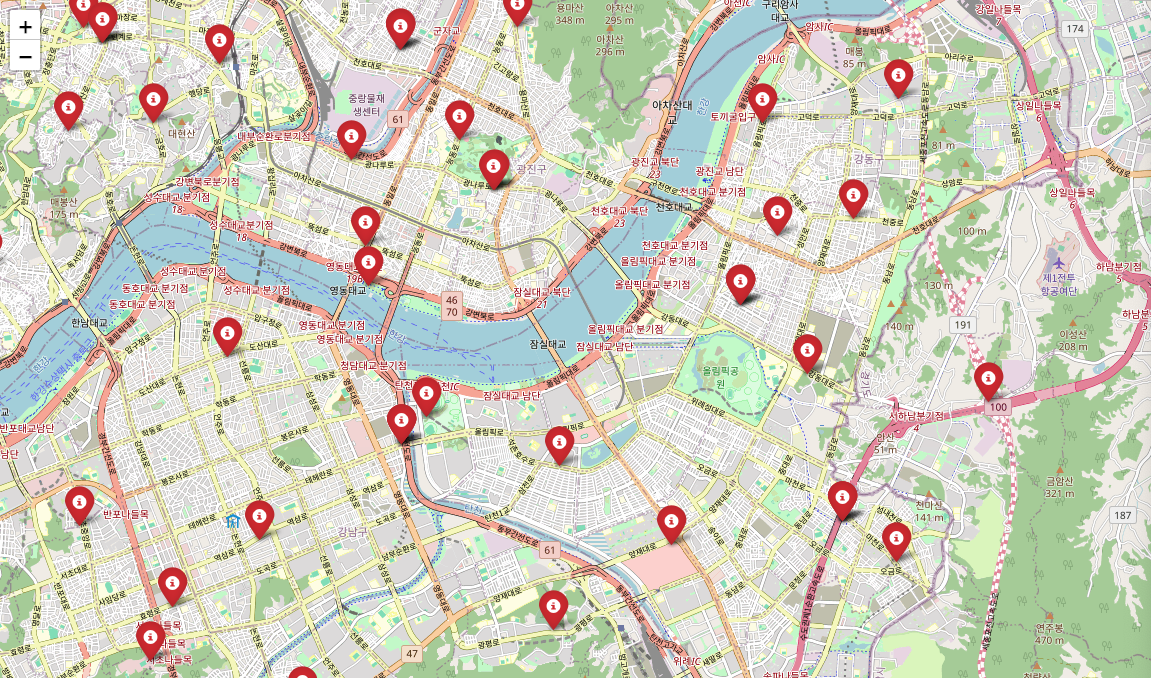
지도 시각화
import folium
from folium.plugins import MarkerCluster
# 데이터 불러오기
df_map = pd.read_csv('서울시 서소위치 위치정보 (좌표계_ WGS1984).csv', encoding='cp949')
# 지도 생성
center = df_map.iloc[0]
map = folium.Map(location=[center['위도'], center['경도']], zoom_start=11)
# 마커 추가
for _, row in df_map.iterrows():
folium.Marker(
location=[row['위도'], row['경도']],
icon=folium.Icon(color='red', icon='info-sign'),
popup=folium.Popup(f"<h5>{row['서소이름']}</h5>", max_width=300),
).add_to(map)
map
후기 및 추천
이번 강의에서는 공공데이터를 활용하여 파이썬으로 데이터를 분석하는 과정을 학습하였습니다. 데이터의 전처리, 결측치 처리, 그룹화 및 집계 등 실무에서 유용하게 사용할 수 있는 내용을 포함하고 있어 매우 유익한 강의였습니다. 초보자도 쉽게 따라할 수 있도록 설명해주셔서 많은 도움이 되었습니다. 다음 강의도 기대됩니다.
'Data Analytics > Online Course' 카테고리의 다른 글
| [메타코드 강의 후기] SQL 데이터 분석 (2/3) (0) | 2024.07.14 |
|---|---|
| [강의 후기] SQL 데이터 분석 (1/3) (1) | 2024.07.14 |
| [메타코드 강의 후기] Python 데이터분석 | 파이썬 기초 (0) | 2024.07.02 |
| [강의 후기] 파이썬 데이터 분석 | 제품 포트폴리오 분석 (0) | 2024.06.30 |
| [강의 후기] 파이썬 데이터 분석 | 데이터 시각화 (7) | 2024.06.29 |
이번에 소개할 강의는 '공공데이터로 Python 데이터분석' 강의입니다. 본 강의는 크게 두 가지 파트로 구성되어 있습니다. 첫 번째는 데이터 분석을 위한 파이썬 기초이며, 두 번째는 데이터 분석 및 시각화입니다.
지난번 글에 이어서 "데이터 분석 및 시각화"에 대해 다루겠습니다. 이번 글에서는 파이썬을 사용한 데이터 분석의 예를 통해 공공데이터를 활용하여 분석하고 시각화하는 방법을 소개합니다.
메타코드M
AI 강의 & 커뮤니티 플랫폼ㅣ300만 조회수 기록한 IT 현직자들의 교육과 함께 하세요
www.metacodes.co.kr
데이터 관련 프로젝트를 할때는 좋은 품질의 데이터를 확보하는 것이 중요합니다. 1. 구축된 데이터를 확보하는것과, 2. 데이터 크롤링이 있습니다.
먼저, 1번을 위해서는 데이터 저작권과 활용 가능 범위를 확인 하는 것이 중요합니다.
대한민국 공식 정부 홈페이지 공공데이터 포털로는 https://www.data.go.kr/ 이 있습니다.
데이터 로드
import pandas as pd
df = pd.read_csv('소방청_구조활동현황_20211231.csv', encoding = 'cp949')
# 데이터 확인
# 1. 상위 5개
df.head()
# 2. 랜덤하게 3개, 시드값
df.sample(3, random_state = 24)
# 3. 하위 5개
df.tail()
데이터 전처리
날짜 및 시간 데이터를 datetime 타입으로 변환하여 시간 계산 및 비교를 용이하게 합니다.
df.info()
# object --> datetime
df['신고년월일'] = pd.to_datetime(df['신고년월일'])
df['출동년월일'] = pd.to_datetime(df['출동년월일'])
df['신고시각'] = pd.to_datetime(df['신고시각'], format='%H:%M')
df['출동시각'] = pd.to_datetime(df['출동시각'], format='%H:%M')
신고일시 및 출동일시 컬럼을 생성하여 시간 관련 데이터를 통합 관리할 수 있게 합니다.
# 문자열 형식으로 다시 변환
df['신고년월일'] = df['신고년월일'].astype(str)
df['출동년월일'] = df['출동년월일'].astype(str)
df['신고시각'] = df['신고시각'].dt.strftime('%H:%M')
df['출동시각'] = df['출동시각'].dt.strftime('%H:%M')
# 신고일시 및 출동일시 컬럼 생성
df['신고일시'] = pd.to_datetime(df['신고년월일'] + ' ' + df['신고시각'])
df['출동일시'] = pd.to_datetime(df['출동년월일'] + ' ' + df['출동시각'])
# 최종 데이터 정보 확인
df.info()
불필요한 컬럼을 삭제하고, 결측치를 특정 값으로 대체하거나 삭제하여 데이터를 정리합니다.
# 불필요한 컬럼 삭제
df_new = df.drop(['신고년월일', '신고시각', '출동년월일', '출동시각'], axis=1)
# 결측치 확인 및 처리
df_new.isna().sum()
# 특정 컬럼의 결측치를 특정 값으로 대체
df_new['발생장소_구'].fillna('세종특별자치시', inplace=True)
# 특정 데이터 필터링 및 삭제
to_drop = (df_new['발생장소_구'] == '경기도') | (df_new['발생장소_구'] == '경상남도')
df_new = df_new[~to_drop]
데이터를 그룹화하여 사고 발생 건수를 집계하고, 피벗 테이블을 생성하여 데이터를 재구성합니다.
# 데이터 그룹화 및 집계
df_new.groupby('발생장소_구')['번호'].count()
# 이중 그룹화 및 집계
double_grouped = df_new.groupby(['발생장소_시', '발생장소_구'])['번호'].count()
df_double = pd.DataFrame(double_grouped).reset_index()
df_double = df_double.rename(columns={'번호': '사고발생건수'})
# 피벗 테이블 생성
df_bouble_pivot = pd.pivot_table(df_new, index=['발생장소_시', '발생장소_구'], aggfunc='size').reset_index(name='사고발생건수')
# 결과 출력
df_bouble_pivot데이터 시각화
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정
plt.rcParams['font.family'] = 'AppleGothic'
plt.figure(figsize = (20,5))
sns.barplot(data = df_bouble_pivot, x = '발생장소_시', y = '사고발생건수', hue = '발생장소_시')
df_seoul = df_seoul[df_seoul['발생장소_구'] != df_seoul['발생장소_시']]
df_seoul_pivot = df_seoul.pivot_table(index = ['발생장소_구'], aggfunc = 'size').reset_index(name = '사고발생건수')
plt.figure(figsize = (20,5))
ax = sns.barplot(df_seoul_pivot, x = '발생장소_구', y = '사고발생건수', hue = '발생장소_구')
plt.figure(figsize = (20,5))
sns.lineplot(data= df_seoul_pivot, x = '발생장소_구', y = '사고발생건수')
df_date_pivot['신고일시'] = pd.to_datetime(df_date_pivot['신고일시']).dt.date
plt.figure(figsize = (20,5))
sns.lineplot(data= df_date_pivot, x = '신고일시', y = '사고발생건수', hue = '발생장소_구')
출동 소요시간 분석
소요시간 계산 및 탐색
# 출동 소요시간 계산
df['출동소요시간'] = (df['출동일시'] - df['신고일시'])
df['출동소요시간_초'] = df['출동소요시간'].dt.total_seconds().astype(int)
df['출동소요시간_분'] = (df['출동소요시간_초'] / 60).astype(int)
# 출동 소요시간 이상치 제거
df = df[~(df['신고일시'] > df['출동일시'])]
소요시간 시각화
# 박스플롯을 통한 소요시간 시각화
plt.figure(figsize=(20, 5))
sns.boxplot(data=df, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
plt.show()
# 소요시간 분포 및 이상치 제거 후 시각화
mean = df['출동소요시간_분'].mean()
std = df['출동소요시간_분'].std()
threshold = mean + 3 * std
df_cleaned = df[df['출동소요시간_분'] <= threshold]
plt.figure(figsize=(20, 5))
sns.boxplot(data=df_cleaned, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
plt.show()
# 구별 평균 출동 소요시간 바플롯 시각화
df_cleaned_pivot = df_cleaned.pivot_table(index='발생장소_구', values='출동소요시간_분', aggfunc='mean').reset_index()
plt.figure(figsize=(20, 5))
sns.barplot(data=df_cleaned_pivot, x='발생장소_구', y='출동소요시간_분', hue='발생장소_구')
# 서울시 평균 소요시간 선 추가
mean_time = df_cleaned_pivot['출동소요시간_분'].mean()
plt.axhline(mean_time, color='black', linestyle='--', label='평균 출동 소요 시간')
plt.legend()
plt.show()
지도 시각화
import folium
from folium.plugins import MarkerCluster
# 데이터 불러오기
df_map = pd.read_csv('서울시 서소위치 위치정보 (좌표계_ WGS1984).csv', encoding='cp949')
# 지도 생성
center = df_map.iloc[0]
map = folium.Map(location=[center['위도'], center['경도']], zoom_start=11)
# 마커 추가
for _, row in df_map.iterrows():
folium.Marker(
location=[row['위도'], row['경도']],
icon=folium.Icon(color='red', icon='info-sign'),
popup=folium.Popup(f"<h5>{row['서소이름']}</h5>", max_width=300),
).add_to(map)
map
후기 및 추천
이번 강의에서는 공공데이터를 활용하여 파이썬으로 데이터를 분석하는 과정을 학습하였습니다. 데이터의 전처리, 결측치 처리, 그룹화 및 집계 등 실무에서 유용하게 사용할 수 있는 내용을 포함하고 있어 매우 유익한 강의였습니다. 초보자도 쉽게 따라할 수 있도록 설명해주셔서 많은 도움이 되었습니다. 다음 강의도 기대됩니다.
'Data Analytics > Online Course' 카테고리의 다른 글
| [메타코드 강의 후기] SQL 데이터 분석 (2/3) (0) | 2024.07.14 |
|---|---|
| [강의 후기] SQL 데이터 분석 (1/3) (1) | 2024.07.14 |
| [메타코드 강의 후기] Python 데이터분석 | 파이썬 기초 (0) | 2024.07.02 |
| [강의 후기] 파이썬 데이터 분석 | 제품 포트폴리오 분석 (0) | 2024.06.30 |
| [강의 후기] 파이썬 데이터 분석 | 데이터 시각화 (7) | 2024.06.29 |