
저는 이전에 파이썬과 SQL 강의를 수강하였기 때문에 배운 내용을 활용하고자 이승훈 강사님의 'SQL과 Python 연결하고 데이터분석 실습' 강의를 수강하였습니다.

Python에서 MySQL 사용하기
mysql.connector 는 MySQL 데이터베이스에 연결하고, SQL 쿼리를 실행하기 위한 Python 라이브러리 입니다.
파이썬 코드 내에서 직접 데이터베이스 작업을 수행할 수 있어, 데이터 분석, 웹 개발 등 다양한 애플리케이션에서 활용 가능합니다.
1. mysql-connector-python 설치
# mysql driver 설치
pip install mysql-connector-python
# 설치 확인
import mysql.connector
2. MySQL 접속 및 종료
# local 에 연결
conn = mysql.connector.connect(
host='localhost',
user='root',
password='123456', # 실제 비밀번호로 변경하세요
database='classicmodels'
)
# 연결 종료
local.close()
쿼리 실행 관련 메서드
cursor.execute()
SQL 쿼리를 실행하는 데 사용됩니다. 변수에 실행하려는 SQL 명령문을 문자열 형태로 입력하면 됩니다.
cursor.description
마지막으로 실행된 execute() 호출에 의해 생성된 결과의 각 컬럼에 대한 메타데이터를 포함한 정보를 반환합니다. 예를 들어 컬럼 이름, 데이터 타입 등의 정보를 포함합니다.
cursor.fetchone()
쿼리 결과에서 다음 행(row)을 반환합니다. 결과가 더 이상 없으면 None을 반환합니다. 일반적으로 단일 결과 행만 필요할 때 사용됩니다.
cursor.fetchall()
쿼리 결과의 모든 행을 한 번에 가져와서 반환합니다. 큰 결과 세트의 경우 많은 메모리를 소비할 수 있으므로 주의가 필요합니다.
cursor.fetchmany(size=숫자)
이 메서드는 쿼리 결과에서 지정된 size 수만큼의 행을 반환합니다. 대량의 데이터를 처리할 때 결과를 더 작은 단위로 나누어 처리하고자 할 때 유용합니다.
cursor.close()
커서 객체를 닫고, 커서에 할당된 모든 리소스를 해제합니다. 커서를 닫은 후에는 더 이상 해당 커서를 사용할 수 없습니다.
conn.close()
데이터베이스 연결을 종료하고, 연결에 할당된 모든 리소스를 해제합니다. 연결을 닫은 후에는 더 이상 해당 연결을 통해 데이터베이스 작업을 수행할 수 없습니다.
2. VIP 고객 식별하기
본 강의에서는 'https://www.mysqltutorial.org/getting-started-with-mysql/mysql-sample-database/'에서 제공하는 샘플 데이터를 사용하였습니다. 데이터에 관한 설명은 다음과 같습니다.

이 쿼리는 orders와 payments 테이블을 조인하여 각 고객의 총 주문 수와 총 지출 금액을 계산합니다. 그런 다음, 총 지출 금액 기준으로 고객을 내림차순 정렬하고, 상위 10명의 VIP 고객을 식별합니다.
# SQL 에서 실행한 후에 가져오기
# VIP 고객 식별 쿼리
vip_customers_query = """
SELECT
o.customerNumber,
COUNT(DISTINCT o.orderNumber) AS order_count,
SUM(p.amount) AS total_spent
FROM
orders o
JOIN
payments p ON o.customerNumber = p.customerNumber
GROUP BY
o.customerNumber
ORDER BY
total_spent DESC
LIMIT 10;
"""
SQL 쿼리 결과를 데이터프레임으로 로드한 후, VIP 고객의 주문 횟수를 바 차트로 시각화합니다.
x축 : 고객 번호, y축 : 주문 횟수
# 데이터 로드
# VIP 고객 데이터를 DataFrame으로 로딩
vip_df = pd.read_sql_query(vip_customers_query, conn)
# 구매 금액 시각화
plt.figure(figsize = (10,6))
plt.bar(vip_df['customerNumber'].astype(str), vip_df['order_count'], color = 'skyblue')
plt.xlabel('Customer Number')
plt.ylabel('Order Count')
plt.title('VIP Customers Order Frequency')
plt.xticks(rotation = 45)
plt.show()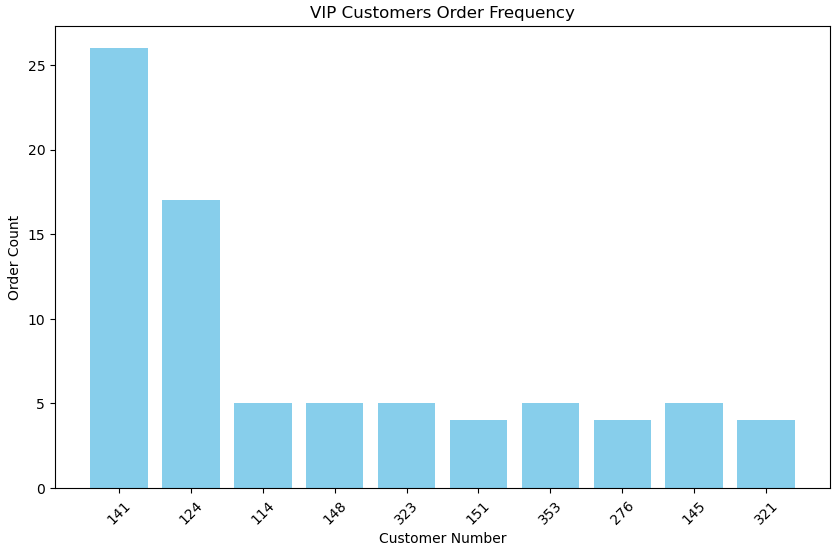
- 141번 고객의 주문 횟수가 가장 많고, 두번째로는 124번 고객의 주문 횟수가 많습니다.
VIP 고객의 주문 금액를 바 차트로 시각화합니다.
x축 : 고객 번호, y축 : 주문 금액
# 구매 금액 시각화
plt.figure(figsize=(10, 6))
plt.bar(vip_df['customerNumber'].astype(str), vip_df['total_spent'], color='lightgreen')
plt.xlabel('Customer Number')
plt.ylabel('Total Spent ($)')
plt.title('VIP Customers Total Spending')
plt.xticks(rotation=45)
plt.show()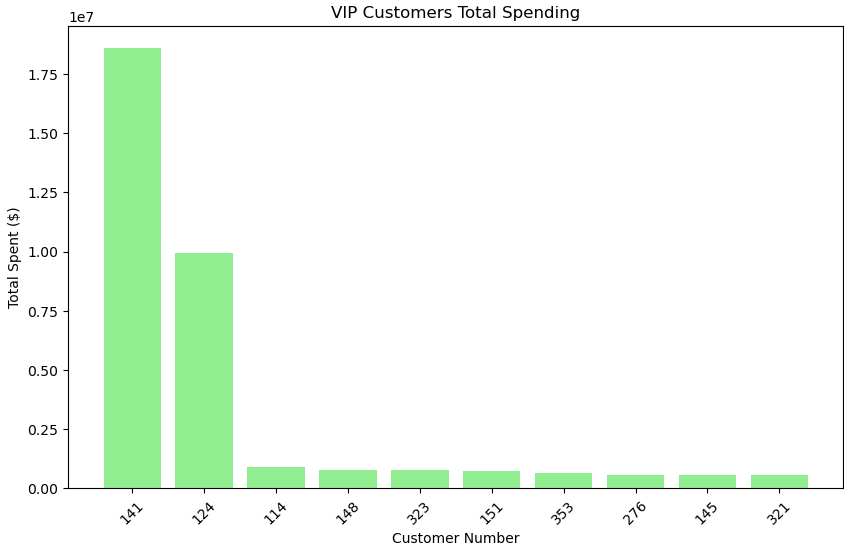
주문 금액 역시 141번 고객과 124번 고객이 많습니다.
다음으로는 VIP 고객의 시간대별 구매 금액 변화를 분석합니다. 구체적으로 2004년과 2005년의 구매 금액을 비교합니다.
# 시간대별 구매 금액 변화 분석 쿼리 실행
purchase_change_query = """
SELECT
p.customerNumber,
SUM(CASE
WHEN p.paymentDate BETWEEN '2004-01-01' AND '2004-12-30' THEN p.amount
ELSE 0
END) AS previous_period_total,
SUM(CASE
WHEN p.paymentDate BETWEEN '2004-12-30' AND '2005-12-31' THEN p.amount
ELSE 0
END) AS recent_period_total
FROM
payments p
INNER JOIN (
SELECT customerNumber
FROM payments
GROUP BY customerNumber
ORDER BY SUM(amount) DESC
) AS vip_customers ON p.customerNumber = vip_customers.customerNumber
GROUP BY
p.customerNumber;
"""
# SQL 쿼리 실행 및 결과 DataFrame으로 변환
purchase_change_df = pd.read_sql_query(purchase_change_query, conn)
# 구매 금액 변화 계산
purchase_change_df['change_in_spending'] = purchase_change_df['recent_period_total'] - purchase_change_df['previous_period_total']
purchase_change_df
# 변화량의 절대값에 따라 상위 10개 고객 선택
top_10_customers_change = purchase_change_df.assign(
abs_change_in_spending=purchase_change_df['change_in_spending'].abs()
).nlargest(10, 'abs_change_in_spending')
# 상위 10개 고객의 원래 변화량 시각화
plt.figure(figsize=(10, 6))
# 여기서는 .loc을 사용해 원래 DataFrame에서 상위 10명 고객의 데이터를 가져옵니다.
plt.bar(top_10_customers_change['customerNumber'].astype(str),
purchase_change_df.loc[top_10_customers_change.index, 'change_in_spending'],
color='orange'
)
plt.xlabel('Customer Number')
plt.ylabel('Change in Total Spent ($)')
plt.title('Top 10 VIP Customers with Largest Changes in Spending')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()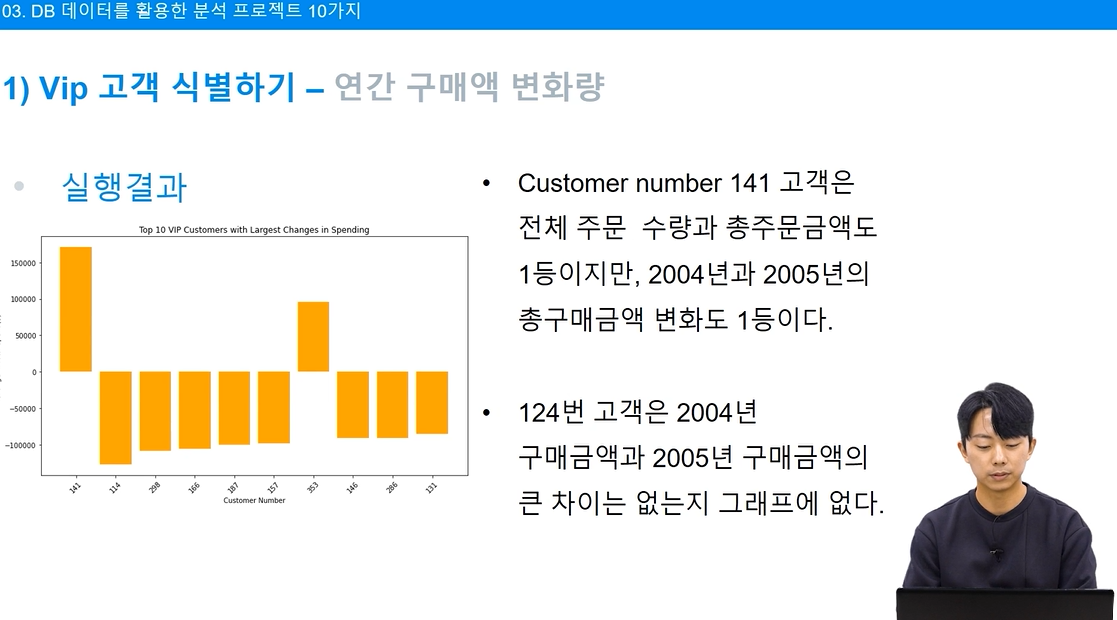
구매 금액 증가
# 구매 금액 변화량이 증가한 상위 10명의 고객을 찾습니다.
increased_spending_top10 = purchase_change_df[purchase_change_df['change_in_spending'] > 0] \
.nlargest(10, 'change_in_spending')
# 증가한 고객의 변화량 시각화
plt.figure(figsize=(10, 6))
plt.bar(increased_spending_top10['customerNumber'].astype(str), increased_spending_top10['change_in_spending'], color='green')
plt.xlabel('Customer Number')
plt.ylabel('Increase in Total Spent ($)')
plt.title('Top 10 Customers with Increased Spending')
plt.xticks(rotation=90);plt.tight_layout();plt.show()
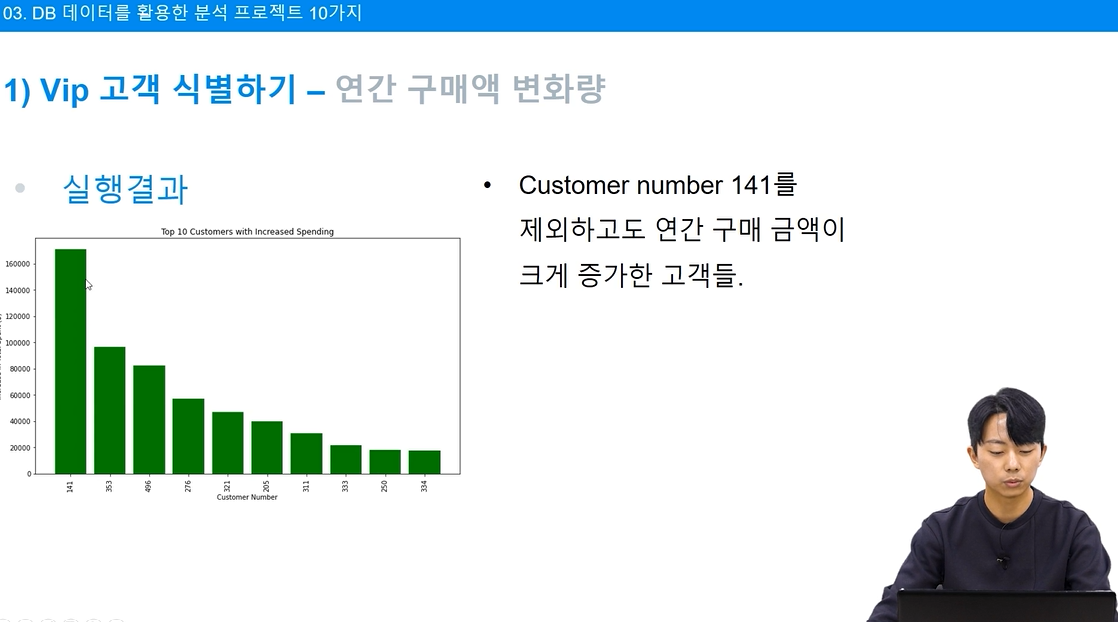
구매 금액 감소
# 구매 금액 변화량이 감소한 상위 10명의 고객을 찾습니다.
decreased_spending_top10 = purchase_change_df[purchase_change_df['change_in_spending'] < 0] \
.nsmallest(10, 'change_in_spending') \
.sort_values(by='change_in_spending', ascending=True) # 감소한 금액이 큰 순서대로 정렬
# 감소한 고객의 변화량 시각화
plt.figure(figsize=(10, 6))
plt.bar(decreased_spending_top10['customerNumber'].astype(str), decreased_spending_top10['change_in_spending'], color='red')
plt.xlabel('Customer Number')
plt.ylabel('Decrease in Total Spent ($)')
plt.title('Top 10 Customers with Decreased Spending')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# 연결 종료
conn.close()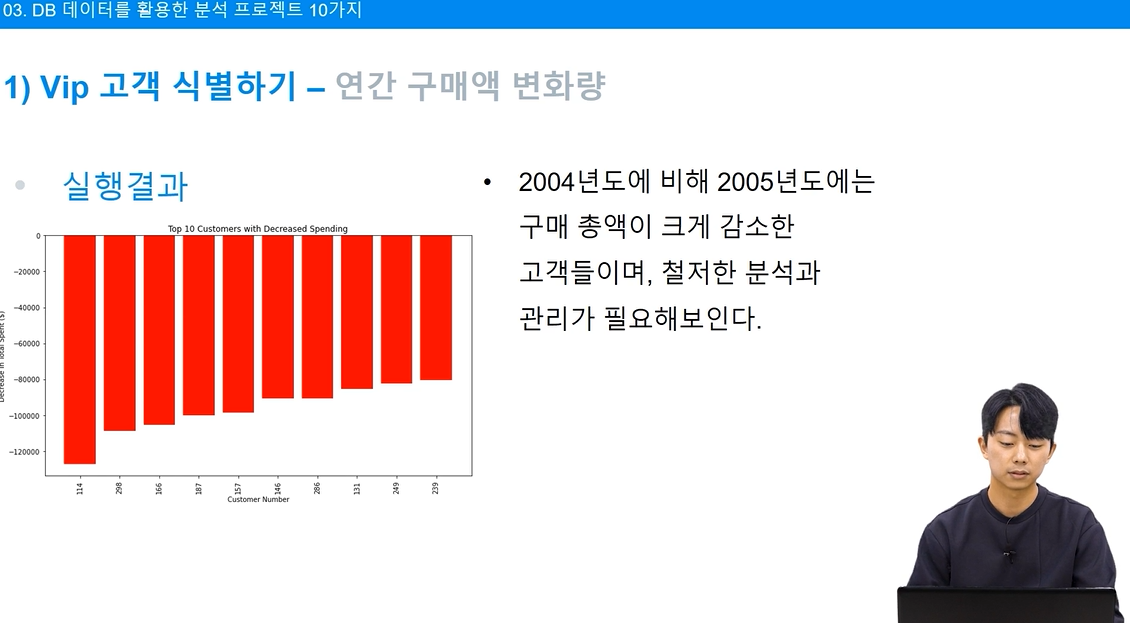
회사 입장에서는 위와 같은 시각화 결과를 활용하여 혜택을 지급 하는 등 전략을 수립하거나, 이탈 고객 방지를 위한 전략을 세울 수 있습니다.
'Data Analytics > Online Course' 카테고리의 다른 글
| 태블로 대시보드 기초 (2/2) (1) | 2024.09.17 |
|---|---|
| 태블로 대시보드 기초 (1/2) (2) | 2024.09.16 |
| [강의 후기] SQL 데이터 분석 (3/3) (0) | 2024.07.21 |
| [메타코드 강의 후기] SQL 데이터 분석 (2/3) (0) | 2024.07.14 |
| [강의 후기] SQL 데이터 분석 (1/3) (1) | 2024.07.14 |
저는 이전에 파이썬과 SQL 강의를 수강하였기 때문에 배운 내용을 활용하고자 이승훈 강사님의 'SQL과 Python 연결하고 데이터분석 실습' 강의를 수강하였습니다.
Python에서 MySQL 사용하기
mysql.connector 는 MySQL 데이터베이스에 연결하고, SQL 쿼리를 실행하기 위한 Python 라이브러리 입니다.
파이썬 코드 내에서 직접 데이터베이스 작업을 수행할 수 있어, 데이터 분석, 웹 개발 등 다양한 애플리케이션에서 활용 가능합니다.
1. mysql-connector-python 설치
# mysql driver 설치
pip install mysql-connector-python
# 설치 확인
import mysql.connector
2. MySQL 접속 및 종료
# local 에 연결
conn = mysql.connector.connect(
host='localhost',
user='root',
password='123456', # 실제 비밀번호로 변경하세요
database='classicmodels'
)
# 연결 종료
local.close()
쿼리 실행 관련 메서드
cursor.execute()
SQL 쿼리를 실행하는 데 사용됩니다. 변수에 실행하려는 SQL 명령문을 문자열 형태로 입력하면 됩니다.
cursor.description
마지막으로 실행된 execute() 호출에 의해 생성된 결과의 각 컬럼에 대한 메타데이터를 포함한 정보를 반환합니다. 예를 들어 컬럼 이름, 데이터 타입 등의 정보를 포함합니다.
cursor.fetchone()
쿼리 결과에서 다음 행(row)을 반환합니다. 결과가 더 이상 없으면 None을 반환합니다. 일반적으로 단일 결과 행만 필요할 때 사용됩니다.
cursor.fetchall()
쿼리 결과의 모든 행을 한 번에 가져와서 반환합니다. 큰 결과 세트의 경우 많은 메모리를 소비할 수 있으므로 주의가 필요합니다.
cursor.fetchmany(size=숫자)
이 메서드는 쿼리 결과에서 지정된 size 수만큼의 행을 반환합니다. 대량의 데이터를 처리할 때 결과를 더 작은 단위로 나누어 처리하고자 할 때 유용합니다.
cursor.close()
커서 객체를 닫고, 커서에 할당된 모든 리소스를 해제합니다. 커서를 닫은 후에는 더 이상 해당 커서를 사용할 수 없습니다.
conn.close()
데이터베이스 연결을 종료하고, 연결에 할당된 모든 리소스를 해제합니다. 연결을 닫은 후에는 더 이상 해당 연결을 통해 데이터베이스 작업을 수행할 수 없습니다.
2. VIP 고객 식별하기
본 강의에서는 'https://www.mysqltutorial.org/getting-started-with-mysql/mysql-sample-database/'에서 제공하는 샘플 데이터를 사용하였습니다. 데이터에 관한 설명은 다음과 같습니다.
이 쿼리는 orders와 payments 테이블을 조인하여 각 고객의 총 주문 수와 총 지출 금액을 계산합니다. 그런 다음, 총 지출 금액 기준으로 고객을 내림차순 정렬하고, 상위 10명의 VIP 고객을 식별합니다.
# SQL 에서 실행한 후에 가져오기
# VIP 고객 식별 쿼리
vip_customers_query = """
SELECT
o.customerNumber,
COUNT(DISTINCT o.orderNumber) AS order_count,
SUM(p.amount) AS total_spent
FROM
orders o
JOIN
payments p ON o.customerNumber = p.customerNumber
GROUP BY
o.customerNumber
ORDER BY
total_spent DESC
LIMIT 10;
"""
SQL 쿼리 결과를 데이터프레임으로 로드한 후, VIP 고객의 주문 횟수를 바 차트로 시각화합니다.
x축 : 고객 번호, y축 : 주문 횟수
# 데이터 로드
# VIP 고객 데이터를 DataFrame으로 로딩
vip_df = pd.read_sql_query(vip_customers_query, conn)
# 구매 금액 시각화
plt.figure(figsize = (10,6))
plt.bar(vip_df['customerNumber'].astype(str), vip_df['order_count'], color = 'skyblue')
plt.xlabel('Customer Number')
plt.ylabel('Order Count')
plt.title('VIP Customers Order Frequency')
plt.xticks(rotation = 45)
plt.show()- 141번 고객의 주문 횟수가 가장 많고, 두번째로는 124번 고객의 주문 횟수가 많습니다.
VIP 고객의 주문 금액를 바 차트로 시각화합니다.
x축 : 고객 번호, y축 : 주문 금액
# 구매 금액 시각화
plt.figure(figsize=(10, 6))
plt.bar(vip_df['customerNumber'].astype(str), vip_df['total_spent'], color='lightgreen')
plt.xlabel('Customer Number')
plt.ylabel('Total Spent ($)')
plt.title('VIP Customers Total Spending')
plt.xticks(rotation=45)
plt.show()주문 금액 역시 141번 고객과 124번 고객이 많습니다.
다음으로는 VIP 고객의 시간대별 구매 금액 변화를 분석합니다. 구체적으로 2004년과 2005년의 구매 금액을 비교합니다.
# 시간대별 구매 금액 변화 분석 쿼리 실행
purchase_change_query = """
SELECT
p.customerNumber,
SUM(CASE
WHEN p.paymentDate BETWEEN '2004-01-01' AND '2004-12-30' THEN p.amount
ELSE 0
END) AS previous_period_total,
SUM(CASE
WHEN p.paymentDate BETWEEN '2004-12-30' AND '2005-12-31' THEN p.amount
ELSE 0
END) AS recent_period_total
FROM
payments p
INNER JOIN (
SELECT customerNumber
FROM payments
GROUP BY customerNumber
ORDER BY SUM(amount) DESC
) AS vip_customers ON p.customerNumber = vip_customers.customerNumber
GROUP BY
p.customerNumber;
"""
# SQL 쿼리 실행 및 결과 DataFrame으로 변환
purchase_change_df = pd.read_sql_query(purchase_change_query, conn)
# 구매 금액 변화 계산
purchase_change_df['change_in_spending'] = purchase_change_df['recent_period_total'] - purchase_change_df['previous_period_total']
purchase_change_df
# 변화량의 절대값에 따라 상위 10개 고객 선택
top_10_customers_change = purchase_change_df.assign(
abs_change_in_spending=purchase_change_df['change_in_spending'].abs()
).nlargest(10, 'abs_change_in_spending')
# 상위 10개 고객의 원래 변화량 시각화
plt.figure(figsize=(10, 6))
# 여기서는 .loc을 사용해 원래 DataFrame에서 상위 10명 고객의 데이터를 가져옵니다.
plt.bar(top_10_customers_change['customerNumber'].astype(str),
purchase_change_df.loc[top_10_customers_change.index, 'change_in_spending'],
color='orange'
)
plt.xlabel('Customer Number')
plt.ylabel('Change in Total Spent ($)')
plt.title('Top 10 VIP Customers with Largest Changes in Spending')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()구매 금액 증가
# 구매 금액 변화량이 증가한 상위 10명의 고객을 찾습니다.
increased_spending_top10 = purchase_change_df[purchase_change_df['change_in_spending'] > 0] \
.nlargest(10, 'change_in_spending')
# 증가한 고객의 변화량 시각화
plt.figure(figsize=(10, 6))
plt.bar(increased_spending_top10['customerNumber'].astype(str), increased_spending_top10['change_in_spending'], color='green')
plt.xlabel('Customer Number')
plt.ylabel('Increase in Total Spent ($)')
plt.title('Top 10 Customers with Increased Spending')
plt.xticks(rotation=90);plt.tight_layout();plt.show()
구매 금액 감소
# 구매 금액 변화량이 감소한 상위 10명의 고객을 찾습니다.
decreased_spending_top10 = purchase_change_df[purchase_change_df['change_in_spending'] < 0] \
.nsmallest(10, 'change_in_spending') \
.sort_values(by='change_in_spending', ascending=True) # 감소한 금액이 큰 순서대로 정렬
# 감소한 고객의 변화량 시각화
plt.figure(figsize=(10, 6))
plt.bar(decreased_spending_top10['customerNumber'].astype(str), decreased_spending_top10['change_in_spending'], color='red')
plt.xlabel('Customer Number')
plt.ylabel('Decrease in Total Spent ($)')
plt.title('Top 10 Customers with Decreased Spending')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# 연결 종료
conn.close()
회사 입장에서는 위와 같은 시각화 결과를 활용하여 혜택을 지급 하는 등 전략을 수립하거나, 이탈 고객 방지를 위한 전략을 세울 수 있습니다.
'Data Analytics > Online Course' 카테고리의 다른 글
| 태블로 대시보드 기초 (2/2) (1) | 2024.09.17 |
|---|---|
| 태블로 대시보드 기초 (1/2) (2) | 2024.09.16 |
| [강의 후기] SQL 데이터 분석 (3/3) (0) | 2024.07.21 |
| [메타코드 강의 후기] SQL 데이터 분석 (2/3) (0) | 2024.07.14 |
| [강의 후기] SQL 데이터 분석 (1/3) (1) | 2024.07.14 |